Open the terminal and log in as root or you use sudo before each command with another user.
Working on a Linux system operating: Centos/REHL
Search for JDK on CentOS
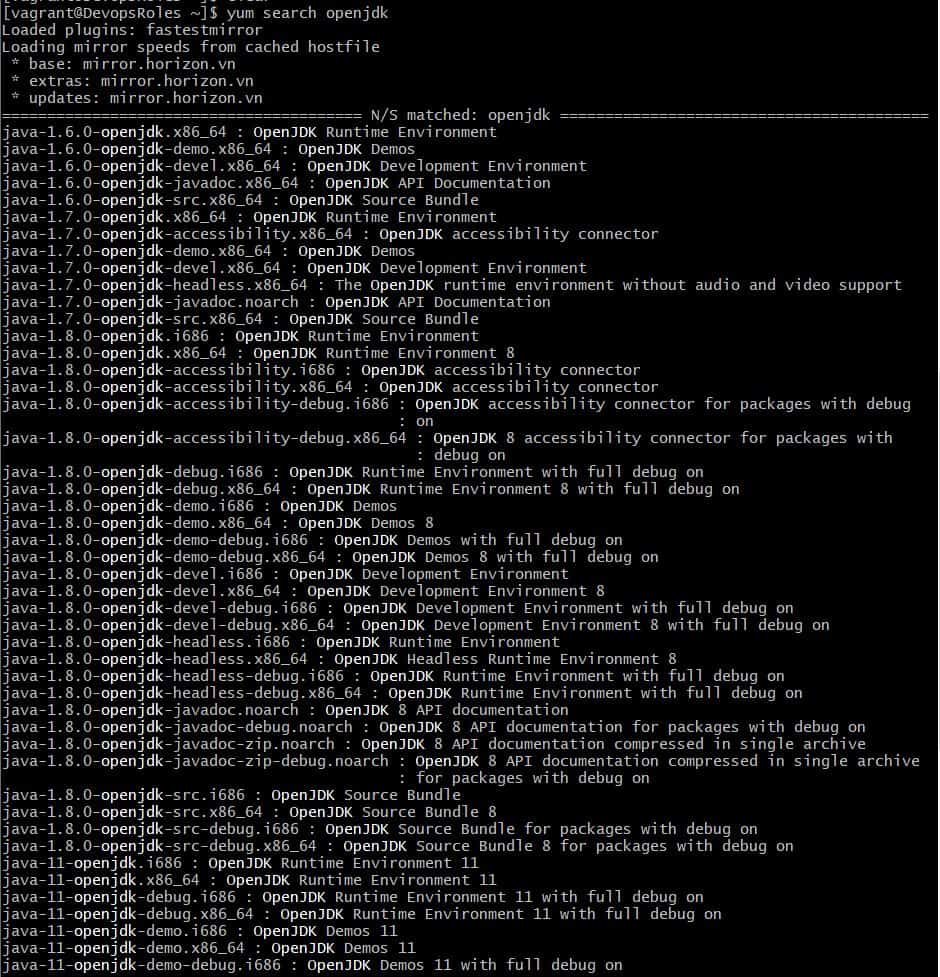
You use the command below to search the packages
$ yum search openjdk
The output terminal console as below
Install JDK 1.8
$ sudo yum install java-1.8.0-openjdk
Confirmation is complete when the installed Java version is displayed.
$ java --version
# Output
# openjdk version "1.8.0_212"
# OpenJDK Runtime Environment (build 1.8.0_212-b04)
# OpenJDK 64-Bit Server VM (build 25.212-b04, mixed mode)
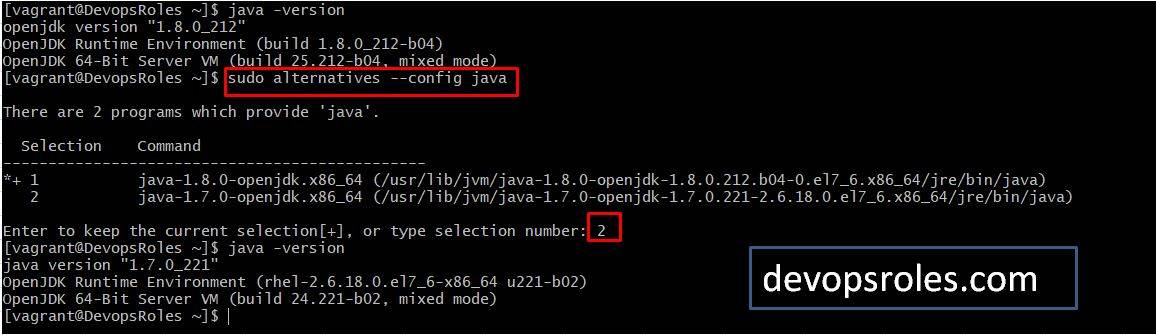
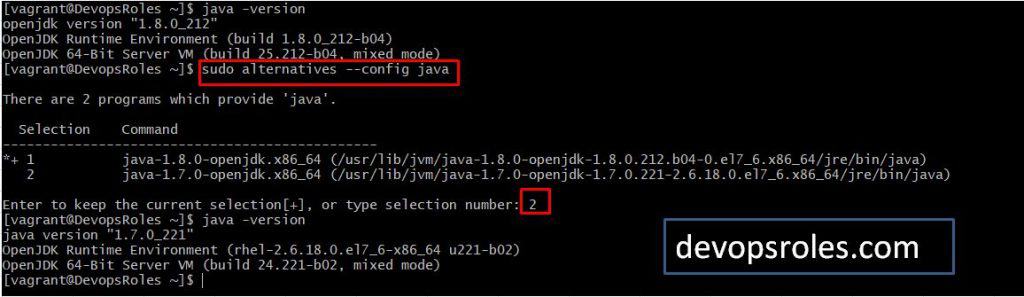
How to switch JDK 7 to JDK 8
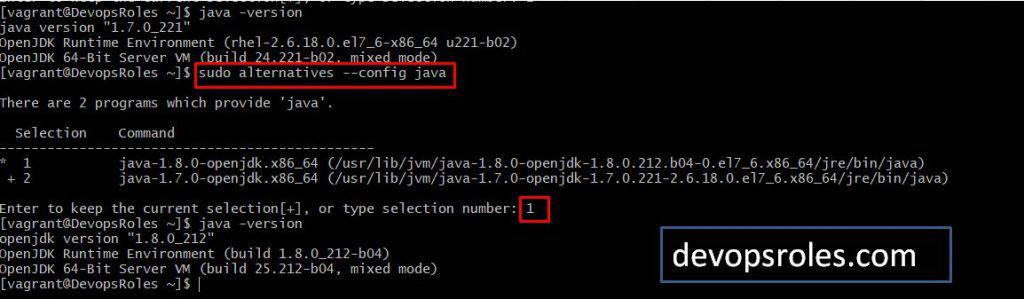
Use the command “sudo alternatives –config java” to switch to JDK.
How to switch JDK 8 to JDK 7
Conclusion
Through the article, How to Install JDK on CentOS step by step. How to switch between JDK 7 and JDK 8? as above. I hope will this your helpful. Thank you for reading the DevopsRoles page!
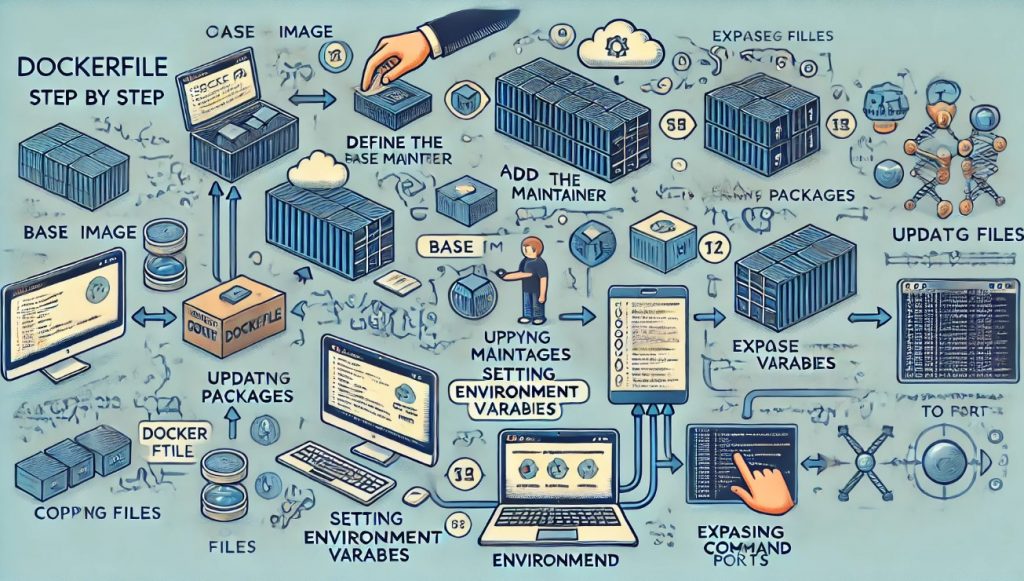
Creating efficient and reliable Docker images starts with a well-crafted Dockerfile step by step. In this article, we will provide a step-by-step guide to writing Dockerfiles, covering essential commands, best practices, and tips to optimize your Docker workflow. Whether you are new to Docker or looking to enhance your skills, this comprehensive guide will help you create Dockerfiles that streamline your development and deployment processes. For a detailed walkthrough, visit Dockerfile Step-by-Step.
After each build step, Docker takes a snapshot of the resulting image. You can force a rebuild with docker build –no-cache
Docker JSON syntax
Most Dockerfile arguments
Plain string format:
RUN yum install -y nginx
JSON format list:
RUN ["yum", "install", "-y", "nginx"]
COPY, ENV, EXPOSE in Dockerfile
Example Dockerfile
FROM centos:7
RUN yum update -y
RUN yum install -y nginx
# make utf-8 enabled by default
ENV LANG en_US.utf8
COPY index.html /usr/share/nginx/html/index.html
EXPOSE 80 443
CMD ["nginx", "-g", "daemon off;"]
VOLUME in Dockerfile
For example Dockerfile
VOLUME ["/etc/nginx/"]
ENTRYPOINT vs CMD in Dockerfile
#For example
CMD ["nginx", "-g", "daemon off;"]
ENTRYPOINT ["/docker-entrypoint.sh"]
You will use ENTRYPOINT and CMD together
ENTRYPOINT will define the base command for our container.
CMD will define the default parameter(s) for this command.
They both have to use JSON syntax.
More
MAINTAINER: Set the Author field of the generated images. Ex: MAINTAINER Huu Phan “huupv@gmail.com”
ADD: Copies new files, directories, or remote files to the container. Invalidates caches. Avoid ADD and use COPY instead. Ex: ADD build-nginx /tmp/build-nginx
STOPSIGNAL: Sets the system call signal that will be sent to the container to exit. Ex: STOPSIGNAL SIGINT
WORKDIR: Sets the working directory. Ex: WORKDIR /etc/nginx
USER: Sets the username for following RUN / CMD / ENTRYPOINT commands. Ex: USER nginx
LABEL: Apply key/value metadata to your images, containers, or daemons. Ex: LABEL architecture=”amd64″
ARG: Defines a build-time variable. Ex: ARG buildno
ONBUILD: Adds a trigger instruction when the image is used as the base for another build. Ex: ONBUILD COPY . /app/src
Conclusion
A solid understanding of Dockerfile construction is crucial for leveraging the full potential of Docker in your projects. This step-by-step guide aims to equip you with the knowledge and techniques to create efficient and effective Dockerfiles.
By following these guidelines, you can ensure smoother builds, reduced image sizes, and enhanced performance in your Docker environments. To stay updated with the latest tips and best practices, be sure to visit Dockerfile Step-by-Step. Let this guide be your roadmap to mastering Dockerfile creation.
Ansible is a well-known structure management tool. Ansible displays the message in JSON format, explaining the structure of the system with YAML. Now, let’s go Jenkins install Plug-in Ansible.
Refer to install Ansible and Jenkins as the link below
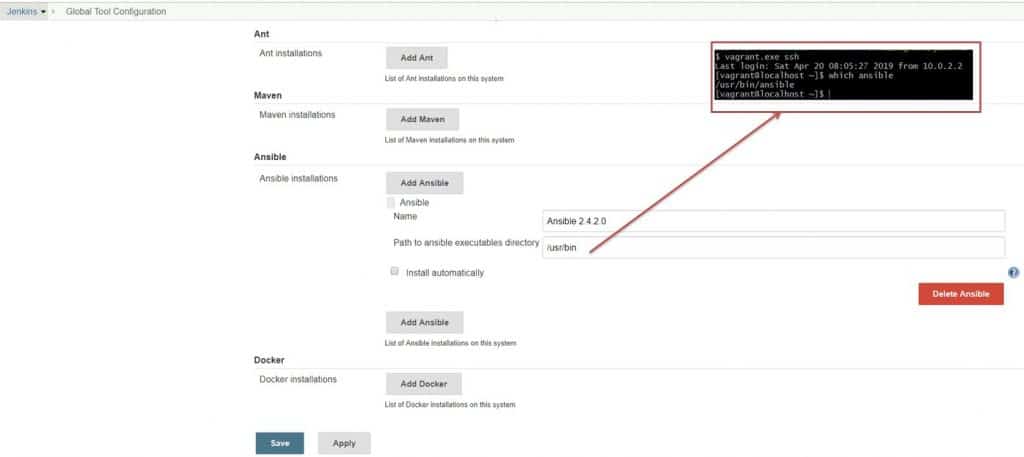
Specify the Ansible implementation directory. Manage Jenkins -> Global Tool Configuration as the picture below
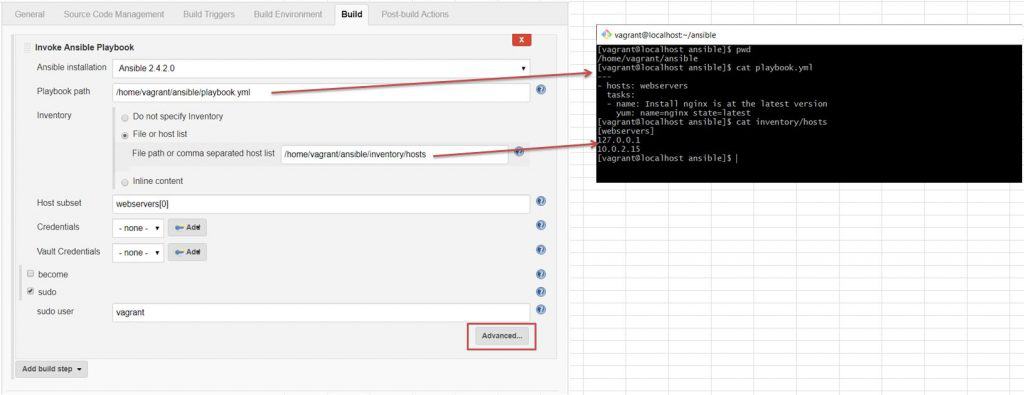
Configure job run Ansible Playbook
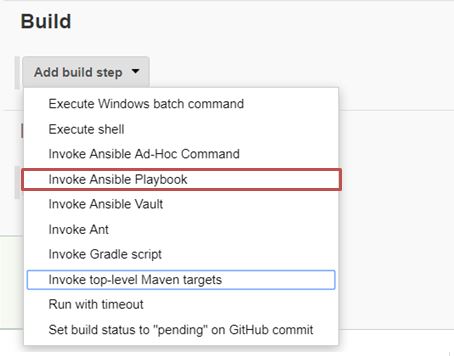
Create job –> configure job –> Add build step as the picture below
My example
Invoke Ansible Playbook as in the picture below
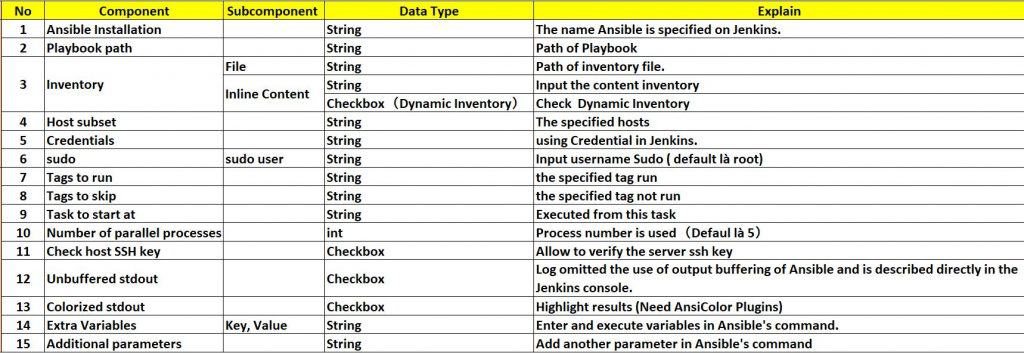
The explained component in Invoke Ansible Playbook as the picture below
Conclusion
Integrating Jenkins and Ansible not only automates the deployment process but also enhances the performance and reliability of your system. Through this detailed guide on installing the Ansible plugin on Jenkins, you can clearly see the benefits this integration brings. By automating configuration management and deployment tasks, you can focus more on developing and improving your products, minimizing risks and errors during deployment. Start integrating Jenkins and Ansible today to experience a significant difference in your DevOps processes.
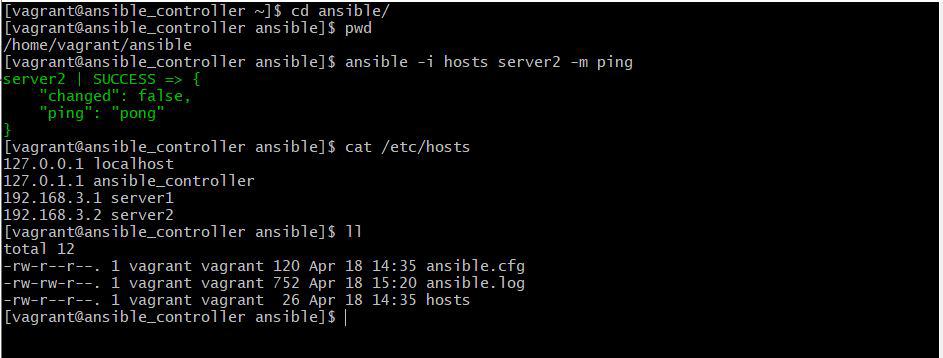
Vagrant is a Configuration management tool. In this tutorial, I will use Vagrant to create an Ansible practice environment. Quickstart Vagrant create ansible your environment developer.
In this tutorial, How to install on Linux. is part of the bind-utils package. The package bind-utils is not yet installed on Linux, then you type command not found on Linux.
To install nslookup on Linux, you need to install the dnsutils package, which contains the nslookup utility. The process for installing the package can vary depending on the Linux distribution you are using. Here are the commands for some popular distributions:
Once the installation is complete, you can use nslookup from the command line.
[vagrant@DevopsRoles ~]$ nslookup x.x.x.x
Conclusion
In this guide, we have covered how to install and use the nslookup command on Linux, specifically for CentOS and Ubuntu. Whether you’re troubleshooting DNS issues or simply querying domain name records, nslookup is a powerful and essential tool for network administrators and IT professionals.
By following the simple installation steps, you can quickly enable nslookup on your system and start resolving domain names with ease. If you encounter any issues, ensure that your system’s package manager is up to date and that you have the necessary permissions to install packages.
We hope this guide has been helpful! If you have any questions or need further assistance, feel free to leave a comment or check out our other Linux tutorials. Thank you for reading the DevopsRoles page!
In this tutorial, we will explore how to use TKPROF with a trace analyzer to trace SQL in an Oracle Database Server. Optimizing SQL performance is crucial for the efficiency and responsiveness of your database applications. One of the powerful tools available for this purpose is TKPROF, a trace file analyzer provided by Oracle.
This guide will introduce you to TKPROF and show you how to use it effectively to trace and analyze SQL performance. By understanding and utilizing TKPROF, you can gain deep insights into your SQL execution, identify performance bottlenecks, and make informed optimizations to enhance your database’s performance.
Syntax of the TKPROF Command
The TKPROF command has several options that allow you to customize its behavior. Here is the syntax:
table=schema.tablename: Use 'schema.tablename' with 'explain=' option.
explain=user/password: Connect to ORACLE and issue EXPLAIN PLAN.
print=integer: List only the first 'integer' SQL statements.
aggregate=yes|no: Aggregate multiple trace files.
insert=filename: List SQL statements and data inside INSERT statements.
sys=no: TKPROF does not list SQL statements run as user SYS.
record=filename: Record non-recursive statements found in the trace file.
waits=yes|no: Record summary for any wait events found in the trace file.
sort=option: Set of zero or more of the following sort options:
prscnt: number of times parse was called
prscpu: CPU time parsing
prsela: elapsed time parsing
prsdsk: number of disk reads during parse
prsqry: number of buffers for consistent read during parse
prscu: number of buffers for current read during parse
prsmis: number of misses in library cache during parse
execnt: number of times execute was called
execpu: CPU time spent executing
exeela: elapsed time executing
exedsk: number of disk reads during execute
exeqry: number of buffers for consistent read during execute
execu: number of buffers for current read during execute
exerow: number of rows processed during execute
exemis: number of library cache misses during execute
fchcnt: number of times fetch was called
fchcpu: CPU time spent fetching
fchela: elapsed time fetching
fchdsk: number of disk reads during fetch
fchqry: number of buffers for consistent read during fetch
fchcu: number of buffers for current read during fetch
fchrow: number of rows fetched
userid: user ID of the user that parsed the cursor
How to Use Trace Analyzer to Trace SQL
Connect to the Database
[oracle11g@DBdevopsroles ~]$ sqlplus DBUSER/DBUSER@ORACLE_SID
SQL> set termout off
SQL> alter session set timed_statistics = true;
SQL> alter session set sql_trace = true;
SQL> SELECT COUNT(*) from tablename01;
SQL> alter session set sql_trace = false;
In this tutorial, we covered how to use the TKPROF command with a trace analyzer to trace SQL in an Oracle Database. Using TKPROF to analyze SQL performance is an invaluable skill for any database administrator or developer. By following the steps outlined in this guide, you should now be able to trace and analyze SQL execution efficiently, uncover performance issues, and implement necessary optimizations.
Continuous monitoring and analysis with TKPROF will ensure that your SQL queries run smoothly and efficiently, contributing to the overall health and performance of your database systems. Keep exploring and mastering TKPROF to become proficient in SQL performance tuning. Thank you for reading the DevopsRoles page!
In this tutorial, How to install Prometheus on RHEL / CentOS 7. Prometheus is an open-source applications and microservices. Prometheus releases Github
cd /tmp
export RELEASE=2.8.1
wget https://github.com/prometheus/prometheus/releases/download/v${RELEASE}/prometheus-${RELEASE}.linux-amd64.tar.gz
tar xvf prometheus-${RELEASE}.linux-amd64.tar.gz
cd prometheus-${RELEASE}.linux-amd64/
Copy Prometheus binary, consoles and console_libraries
# Global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
scrape_timeout: 15s # scrape_timeout is set to the global default (10s).
# A scrape configuration containing exactly one endpoint to scrape:# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:9090']
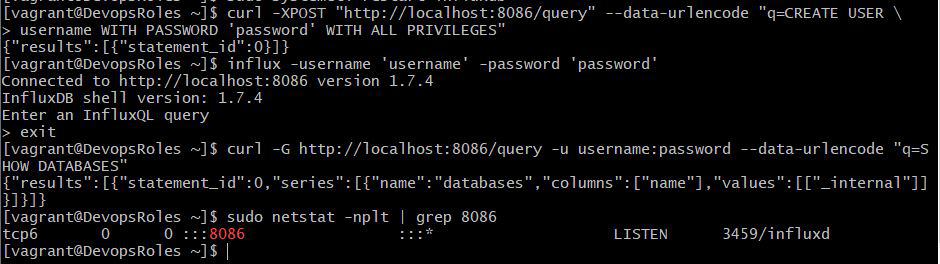
In this tutorial, How to install InfluxDB on RHEL / Centos 7. InfluxDB is an open-source time-series database. It is High availability storage and optimized for fast and metrics analysis.
To install InfluxDB on RHEL/CentOS 7, you can follow the steps below:
[vagrant@DevopsRoles ~]$ curl -XPOST "http://localhost:8086/query" --data-urlencode "q=CREATE USER \
username WITH PASSWORD 'password' WITH ALL PRIVILEGES"
You need to run any Influxdb commands on the terminal with a specific username and password.