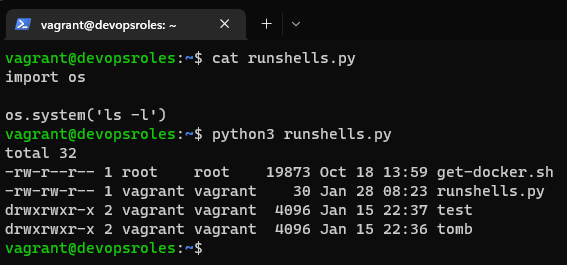
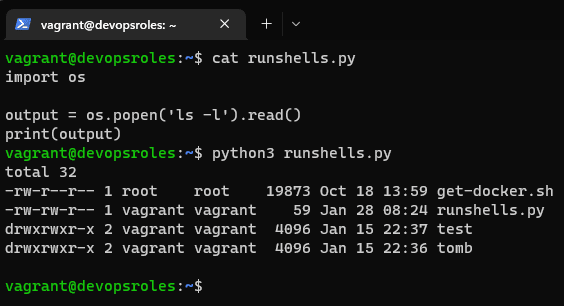
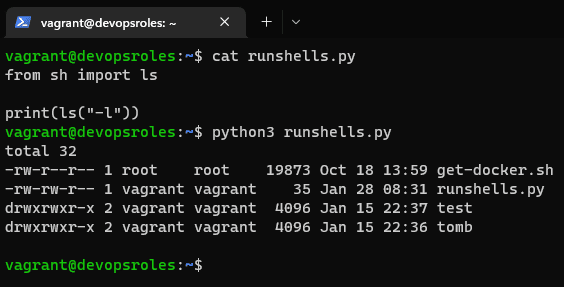
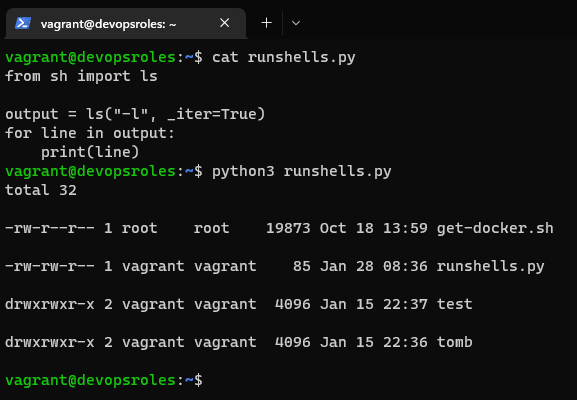
Introduction
SQL (Structured Query Language) databases have been the backbone of data management in modern applications for decades. Whether you’re building a web application, performing data analysis, or automating processes, working with SQL databases is a crucial skill. Python, one of the most popular programming languages, makes interacting with SQL databases straightforward and efficient.
In this guide, we’ll explore how to use SQL databases with Python. From connecting to the database to executing queries and retrieving data, we’ll walk you through essential techniques that every Python developer should know. Whether you’re a beginner or an experienced programmer, you’ll find practical examples and tips to enhance your Python-DB integration.
What is SQL?
SQL: The Language of Databases
SQL is a standard programming language designed for managing and manipulating relational databases. With SQL, you can create, read, update, and delete (CRUD operations) data stored in tables. The language is known for its simplicity and powerful querying capabilities.
Basic SQL Commands:
- SELECT: Retrieves data from one or more tables.
- INSERT: Adds new data into a table.
- UPDATE: Modifies existing data in a table.
- DELETE: Removes data from a table.
- CREATE: Creates a new table or database.
- DROP: Deletes a table or database.
SQL is widely used in various industries, including banking, e-commerce, healthcare, and education. As Python’s popularity grows, the need to integrate SQL databases with Python-based applications has become increasingly important.
How to Use SQL Databases with Python
Setting Up Your Environment
Before you can use SQL databases with Python, you need to install the required libraries. Python’s built-in library, sqlite3, is suitable for lightweight databases, but if you are working with MySQL, PostgreSQL, or other databases, you may need additional libraries.
Installing MySQL Connector:
For MySQL databases, use the mysql-connector-python package. You can install it with pip:
pip install mysql-connector-python
Installing PostgreSQL Adapter:
To interact with PostgreSQL, use psycopg2:
pip install psycopg2
Connecting to the Database
Once the necessary libraries are installed, you’ll need to establish a connection to the database.
Example: Connecting to SQLite
import sqlite3
# Establish connection to SQLite database
connection = sqlite3.connect("example.db")
# Create a cursor object to interact with the database
cursor = connection.cursor()
Example: Connecting to MySQL
import mysql.connector
# Establish connection to MySQL database
connection = mysql.connector.connect(
host="localhost",
user="yourusername",
password="yourpassword",
database="yourdatabase"
)
# Create a cursor object to interact with the database
cursor = connection.cursor()
Once the connection is established, you can begin executing SQL queries.
Executing SQL Queries with Python
Python provides several methods to execute SQL queries. The most common method is using a cursor object, which allows you to run commands and fetch results from the database.
Example 1: Executing a Simple SELECT Query
# Execute a simple SELECT query
cursor.execute("SELECT * FROM users")
# Fetch all results
results = cursor.fetchall()
# Display results
for row in results:
print(row)
Example 2: Inserting Data into a Table
# Inserting data into the 'users' table
cursor.execute("INSERT INTO users (name, age) VALUES (%s, %s)", ("John Doe", 30))
# Commit changes to the database
connection.commit()
Example 3: Updating Data
# Update the 'age' of a user
cursor.execute("UPDATE users SET age = %s WHERE name = %s", (35, "John Doe"))
# Commit changes
connection.commit()
Example 4: Deleting Data
# Delete a user from the 'users' table
cursor.execute("DELETE FROM users WHERE name = %s", ("John Doe",))
# Commit changes
connection.commit()
Advanced Database Operations
Using Parameters in SQL Queries
Instead of directly inserting data into SQL queries (which can be prone to SQL injection attacks), it’s good practice to use parameterized queries. These queries separate the SQL logic from the data.
cursor.execute("SELECT * FROM users WHERE age > %s", (25,))
This approach improves security and helps prevent SQL injection.
Using Context Managers for Database Connections
It’s a good practice to use Python’s context manager (with statement) for managing database connections. This ensures that the connection is properly closed, even in case of an exception.
import sqlite3
with sqlite3.connect("example.db") as connection:
cursor = connection.cursor()
cursor.execute("SELECT * FROM users")
results = cursor.fetchall()
print(results)
Handling Errors and Exceptions
You should always handle errors and exceptions when working with databases. The try-except block is commonly used to catch SQL-related errors.
try:
cursor.execute("SELECT * FROM non_existing_table")
except sqlite3.Error as e:
print(f"An error occurred: {e}")
Transaction Management
In many cases, you may need to handle multiple database operations as part of a single transaction. Python’s commit() method is used to save changes, while rollback() can be used to undo changes if something goes wrong.
try:
cursor.execute("INSERT INTO users (name, age) VALUES ('Alice', 25)")
cursor.execute("UPDATE users SET age = 26 WHERE name = 'Alice'")
connection.commit()
except:
connection.rollback()
print("Transaction failed. Changes rolled back.")
Best Practices for Using SQL Databases with Python
1. Use Prepared Statements
Prepared statements improve performance and security. They ensure that the same SQL query can be executed multiple times with different parameters.
2. Always Close Database Connections
Always close your database connections after use. Using context managers (with statement) is an efficient way to manage database connections and ensure they are properly closed.
3. Use Transactions
Wrap related operations in a transaction to ensure data consistency and rollback in case of failure.
4. Optimize SQL Queries
Ensure your SQL queries are optimized for better performance, especially when dealing with large datasets. Use indexes, avoid using SELECT *, and optimize joins.
Frequently Asked Questions (FAQ)
1. How do I connect Python to SQL Server?
To connect Python to SQL Server, you can use the pyodbc library.
pip install pyodbc
Here’s how you can connect:
import pyodbc
connection = pyodbc.connect(
"DRIVER={ODBC Driver 17 for SQL Server};"
"SERVER=your_server_name;"
"DATABASE=your_database_name;"
"UID=your_username;"
"PWD=your_password"
)
2. Can I use Python with PostgreSQL?
Yes, you can use Python with PostgreSQL by installing the psycopg2 package. You can interact with the PostgreSQL database just like any other SQL database.
3. What is an ORM in Python?
An ORM (Object-Relational Mapping) allows you to work with SQL databases using Python objects. Some popular ORM frameworks for Python include SQLAlchemy and Django ORM.
4. How can I improve SQL query performance?
You can improve SQL query performance by:
- Indexing the right columns
- Using efficient joins
- Avoiding
SELECT * - Analyzing query execution plans

External Links
Conclusion
Learning how to use SQL databases with Python opens the door to many exciting opportunities in programming and data management. Whether you’re working with SQLite, MySQL, PostgreSQL, or any other relational database, Python offers robust tools for executing queries and handling data. By following the practices and examples in this guide, you’ll be able to efficiently integrate SQL databases into your Python projects.
Remember to prioritize security, efficiency, and best practices when working with databases. As you gain experience, you’ll discover more advanced techniques for optimizing your workflows and enhancing performance. Keep experimenting with real-world projects, and soon you’ll be a pro at using SQL with Python! Thank you for reading the DevopsRoles page!