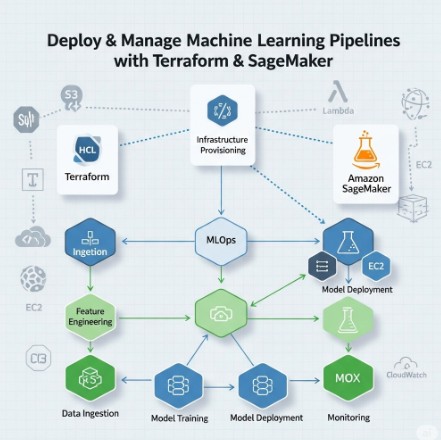
The world of infrastructure as code (IaC) is constantly evolving, driven by the need for greater efficiency, automation, and scalability. HashiCorp, a leader in multi-cloud infrastructure automation, has significantly advanced the field with the launch of its Terraform Cloud Managed Private Cloud (MCP) server, enabling seamless integration with AI and machine learning (ML) capabilities. This article delves into the exciting possibilities offered by HashiCorp Terraform AI, exploring how it empowers developers and DevOps teams to build, manage, and secure their infrastructure more effectively than ever before. We will address the challenges traditional IaC faces and demonstrate how HashiCorp Terraform AI solutions overcome these limitations, paving the way for a more intelligent and automated future.
Understanding the Power of HashiCorp Terraform AI
Traditional IaC workflows, while powerful, often involve repetitive tasks, manual intervention, and a degree of guesswork. Predicting resource needs, optimizing configurations, and troubleshooting issues can be time-consuming and error-prone. HashiCorp Terraform AI changes this paradigm by leveraging the power of AI and ML to automate and enhance several critical aspects of the infrastructure lifecycle.
Enhanced Automation with AI-Driven Predictions
HashiCorp Terraform AI introduces intelligent features that significantly reduce the manual effort associated with infrastructure management. For instance, AI-powered predictive analytics can anticipate future resource requirements based on historical data and current trends, enabling proactive scaling and preventing performance bottlenecks. This predictive capacity minimizes the risk of resource exhaustion and ensures optimal infrastructure utilization.
Intelligent Configuration Optimization
Configuring infrastructure can be complex, often requiring extensive expertise and trial-and-error to achieve optimal performance and security. HashiCorp Terraform AI employs ML algorithms to analyze configurations and suggest improvements. This intelligent optimization leads to more efficient resource allocation, reduced costs, and enhanced system reliability. It helps to avoid common configuration errors and ensure compliance with best practices.
Streamlined Troubleshooting and Anomaly Detection
Identifying and resolving infrastructure issues can be a major challenge. HashiCorp Terraform AI excels in this area by employing advanced anomaly detection techniques. By continuously monitoring infrastructure performance, it can identify unusual patterns and potential problems before they escalate into significant outages or security breaches. This proactive approach significantly improves system stability and reduces downtime.
Implementing HashiCorp Terraform AI: A Practical Guide
Integrating AI into your Terraform workflows is not as daunting as it might seem. The process leverages existing Terraform features and integrates seamlessly with the Terraform Cloud MCP server. While specific implementation details depend on your chosen AI/ML services and your existing infrastructure, the core principles remain consistent.
Step-by-Step Integration Process
- Set up Terraform Cloud MCP Server: Ensure you have a properly configured Terraform Cloud MCP server. This provides a secure and controlled environment for deploying and managing your infrastructure.
- Choose AI/ML Services: Select suitable AI/ML services to integrate with Terraform. Options range from cloud-based offerings (like AWS SageMaker, Google AI Platform, or Azure Machine Learning) to on-premises solutions, depending on your requirements and existing infrastructure.
- Develop Custom Modules: Create custom Terraform modules to interface between Terraform and your chosen AI/ML services. These modules will handle data transfer, model execution, and integration of AI-driven insights into your infrastructure management workflows.
- Implement Data Pipelines: Establish robust data pipelines to feed relevant information from your infrastructure to the AI/ML models. This ensures the AI models receive the necessary data to make accurate predictions and recommendations.
- Monitor and Iterate: Continuously monitor the performance of your AI-powered infrastructure management system. Regularly evaluate the results, iterate on your models, and refine your integration strategies to maximize effectiveness.
Example Code Snippet (Conceptual):
This is a conceptual example and might require adjustments based on your specific AI/ML service and setup. It illustrates how you might integrate predictions into your Terraform configuration:
resource "aws_instance" "example" {
ami = "ami-0c55b31ad2299a701" # Replace with your AMI
instance_type = data.aws_instance_type.example.id
count = var.instance_count + jsondecode(data.aws_lambda_function_invocation.prediction.result).predicted_instances
}
data "aws_lambda_function_invocation" "prediction" {
function_name = "prediction-lambda" # Replace with your lambda function name
input = jsonencode({ instance_count = var.instance_count })
}
# The aws_instance_type data source is needed since you're using it in the resource block
data "aws_instance_type" "example" {
instance_type = "t2.micro" # Example instance type
}
# The var.instance_count variable needs to be defined
variable "instance_count" {
type = number
default = 1
}Addressing Security Concerns with HashiCorp Terraform AI
Security is paramount when integrating AI into infrastructure management. HashiCorp Terraform AI addresses this by emphasizing secure data handling, access control, and robust authentication mechanisms. The Terraform Cloud MCP server offers features to manage access rights and encrypt sensitive data, ensuring that your infrastructure remains protected.
Best Practices for Secure Integration
- Secure Data Transmission: Utilize encrypted channels for all communication between Terraform, your AI/ML services, and your infrastructure.
- Role-Based Access Control: Implement granular access control to limit access to sensitive data and resources.
- Regular Security Audits: Conduct regular security audits to identify and mitigate potential vulnerabilities.
- Data Encryption: Encrypt all sensitive data both in transit and at rest.
Frequently Asked Questions
What are the benefits of using HashiCorp Terraform AI?
HashiCorp Terraform AI offers numerous advantages, including enhanced automation, improved resource utilization, proactive anomaly detection, streamlined troubleshooting, reduced costs, and increased operational efficiency. It empowers organizations to manage their infrastructure with greater speed, accuracy, and reliability.
How does HashiCorp Terraform AI compare to other IaC solutions?
While other IaC solutions exist, HashiCorp Terraform AI distinguishes itself through its seamless integration with AI and ML capabilities. This allows for a level of automation and intelligent optimization not readily available in traditional IaC tools. It streamlines operations, improves resource allocation, and enables proactive issue resolution.
What are the prerequisites for implementing HashiCorp Terraform AI?
Prerequisites include a working knowledge of Terraform, access to a Terraform Cloud MCP server, and a chosen AI/ML service. You’ll also need expertise in developing custom Terraform modules and setting up data pipelines to feed information to your AI/ML models. Familiarity with relevant cloud platforms is beneficial.
Is HashiCorp Terraform AI suitable for all organizations?
The suitability of HashiCorp Terraform AI depends on an organization’s specific needs and resources. Organizations with complex infrastructures, demanding scalability requirements, and a need for advanced automation capabilities will likely benefit most. Those with simpler setups might find the overhead unnecessary. However, the long-term advantages often justify the initial investment.
What is the cost of implementing HashiCorp Terraform AI?
The cost depends on several factors, including the chosen AI/ML services, the complexity of your infrastructure, and the level of customization required. Factors like cloud service provider costs, potential for reduced operational expenses, and increased efficiency must all be weighed.


Conclusion
The advent of HashiCorp Terraform AI marks a significant step forward in the evolution of infrastructure as code. By leveraging the power of AI and ML, it addresses many of the challenges associated with traditional IaC, offering enhanced automation, intelligent optimization, and proactive problem resolution. Implementing HashiCorp Terraform AI requires careful planning and execution, but the resulting improvements in efficiency, scalability, and reliability are well worth the investment. Embrace this powerful tool to build a more robust, resilient, and cost-effective infrastructure for your organization. Remember to prioritize security throughout the integration process. For more detailed information, refer to the official HashiCorp documentation https://www.hashicorp.com/docs/terraform and explore the capabilities of various cloud-based AI/ML platforms. https://aws.amazon.com/machine-learning/ https://cloud.google.com/ai-platform. Thank you for reading the DevopsRoles page!