Terraform Testing has moved from a “nice-to-have” luxury to an absolute survival requirement for modern DevOps engineers.
I’ve seen infrastructure deployments melt down because of a single misplaced variable.
It isn’t pretty. In fact, it’s usually a 3 AM nightmare that costs thousands in downtime.
We need to stop treating Infrastructure as Code (IaC) differently than application code.
If you aren’t testing, you aren’t truly automating.
So, how do we move from manual “plan and pray” to a robust, automated pipeline?

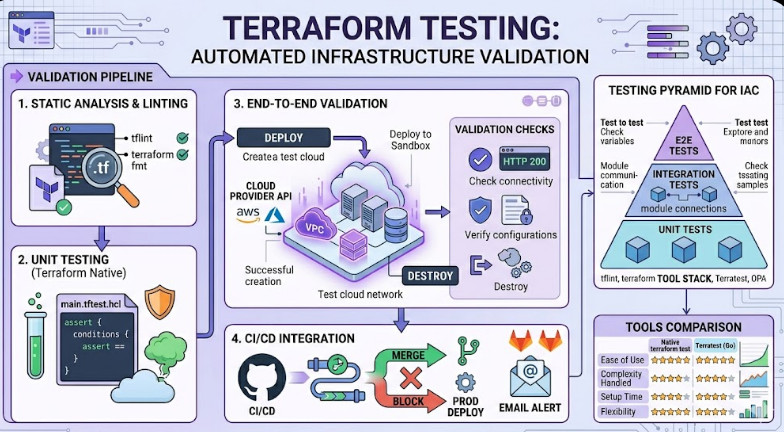
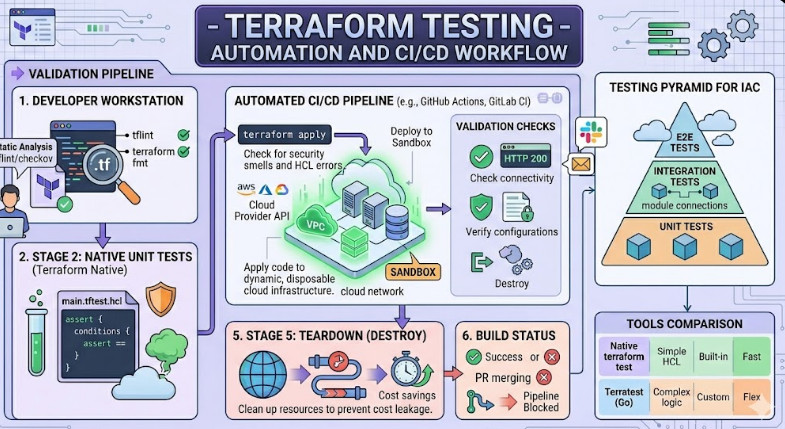
Why Terraform Testing is Your Only Safety Net
The “move fast and break things” mantra works for apps, but it’s lethal for infrastructure.
One bad Terraform apply can delete a production database or open your S3 buckets to the world.
I remember a project three years ago where a junior dev accidentally wiped a VPC peering connection.
The fallout was immediate. Total network isolation for our microservices.
We realized then that manual code reviews aren’t enough to catch logical errors in HCL.
We needed a tiered approach to Terraform Testing that mirrors the classic software testing pyramid.
The Hierarchy of Infrastructure Validation
- Static Analysis: Checking for syntax and security smells without executing code.
- Unit Testing: Testing individual modules in isolation.
- Integration Testing: Ensuring different modules play nice together.
- End-to-End (E2E) Testing: Deploying real resources and verifying their state.
For more details on the initial setup, check the official documentation provided by the original author.
Mastering Static Analysis and Linting
The first step in Terraform Testing is the easiest and most cost-effective.
Tools like `tflint` and `terraform validate` should be your first line of defense.
They catch the “dumb” mistakes before they ever reach your cloud provider.
I personally never commit a line of code without running a linter.
It’s a simple habit that saves hours of debugging later.
You can also use Checkov or Terrascan for security-focused static analysis.
These tools look for “insecure defaults” like unencrypted disks or public SSH access.
# Basic Terraform validation
terraform init
terraform validate
# Running TFLint to catch provider-specific issues
tflint --init
tflint
The Power of Unit Testing in Terraform
How do you know your module actually does what it claims?
Unit testing focuses on the logic of your HCL code.
Since Terraform 1.6, we have a native testing framework that is a total game-changer.
Before this, we had to rely heavily on Go-based tools like Terratest.
Now, you can write Terraform Testing files directly in HCL.
It feels natural. It feels integrated.
Here is how a basic test file looks in the new native framework:
# main.tftest.hcl
variables {
instance_type = "t3.micro"
}
run "verify_instance_type" {
command = plan
assert {
condition = aws_instance.web.instance_type == "t3.micro"
error_message = "The instance type must be t3.micro for cost savings."
}
}
This approach allows you to assert values in your plan without spending a dime on cloud resources.
Does it get better than that?
Actually, it does when we talk about actual resource creation.
Moving to End-to-End Terraform Testing
Static analysis and plans are great, but they don’t catch everything.
Sometimes, the cloud provider rejects your request even if the HCL is valid.
Maybe there’s a quota limit you didn’t know about.
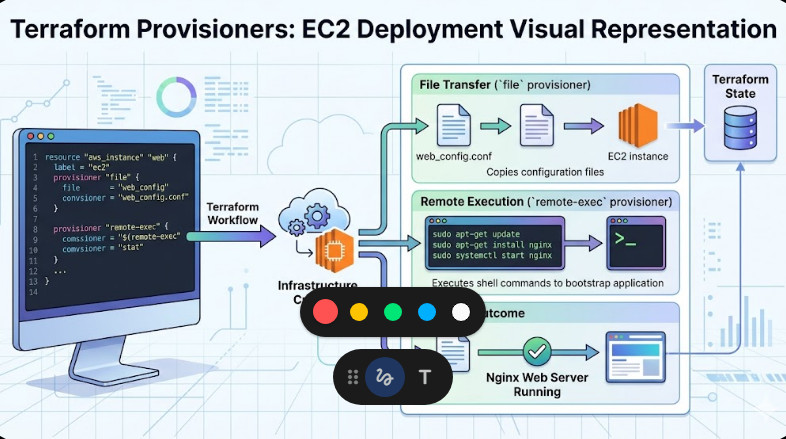
This is where E2E Terraform Testing comes into play.
In this phase, we actually `apply` the code to a sandbox environment.
We verify that the resource exists and functions as expected.
Then, we `destroy` it to keep costs low.
It sounds expensive, but it’s cheaper than a production outage.
I usually recommend running these on a schedule or on specific release branches.
[Internal Link: Managing Cloud Costs in CI/CD]
Implementing Terratest for Complex Scenarios
While the native framework is great, complex scenarios still require Terratest.
Terratest is a Go library that gives you ultimate flexibility.
You can make HTTP requests to your new load balancer to check the response.
You can SSH into an instance and run a command.
It’s the “Gold Standard” for advanced Terraform Testing.
func TestTerraformWebserverExample(t *testing.T) {
opts := &terraform.Options{
TerraformDir: "../examples/webserver",
}
// Clean up at the end of the test
defer terraform.Destroy(t, opts)
// Deploy the infra
terraform.InitAndApply(t, opts)
// Get the output
publicIp := terraform.Output(t, opts, "public_ip")
// Verify it works
url := fmt.Sprintf("http://%s:8080", publicIp)
http_helper.HttpGetWithRetry(t, url, nil, 200, "Hello, World!", 30, 5*time.Second)
}
Is Go harder to learn than HCL? Yes.
Is it worth it for enterprise-grade infrastructure? Absolutely.
Integration with CI/CD Pipelines
Manual testing is better than no testing, but automated Terraform Testing is the goal.
Your CI/CD pipeline should be the gatekeeper.
No code should ever merge to `main` without passing the linting and unit test suite.
I like to use GitHub Actions or GitLab CI for this.
They provide clean environments to run your tests from scratch every time.
This ensures your infrastructure is reproducible.
If it works in the CI, it will work in production.
Well, 99.9% of the time, anyway.
Best Practices for Automated Pipelines
- Keep your test environments isolated using separate AWS accounts or Azure subscriptions.
- Use “Ephemeral” environments that are destroyed immediately after tests finish.
- Parallelize your tests to keep the developer feedback loop short.
- Store your state files securely in a remote backend like S3 with locking.
The Human Element of Infrastructure Code
We often forget that Terraform Testing is also about team confidence.
When a team knows their changes are being validated, they move faster.
Fear is the biggest bottleneck in DevOps.
Testing removes that fear.
It allows for experimentation without catastrophic consequences.
I’ve seen teams double their deployment frequency just by adding basic automated checks.
FAQ: Common Questions About Terraform Testing
- How long should my tests take? Aim for unit tests under 2 minutes and E2E under 15.
- Is Terratest better than the native ‘terraform test’? For simple checks, use native. For complex logic, use Terratest.
- How do I handle secrets in tests? Use environment variables or a dedicated secret manager like HashiCorp Vault.
- Can I test existing infrastructure? Yes, using `terraform plan -detailed-exitcode` or the `import` block.
Conclusion: Embracing a comprehensive Terraform Testing strategy is the only way to scale cloud infrastructure reliably. By combining static analysis, HCL-native unit tests, and robust E2E validation with tools like Terratest, you create a resilient ecosystem where “breaking production” becomes a relic of the past. Start small, lint your code today, and build your testing pyramid one block at a time.

Thank you for reading the DevopsRoles page!