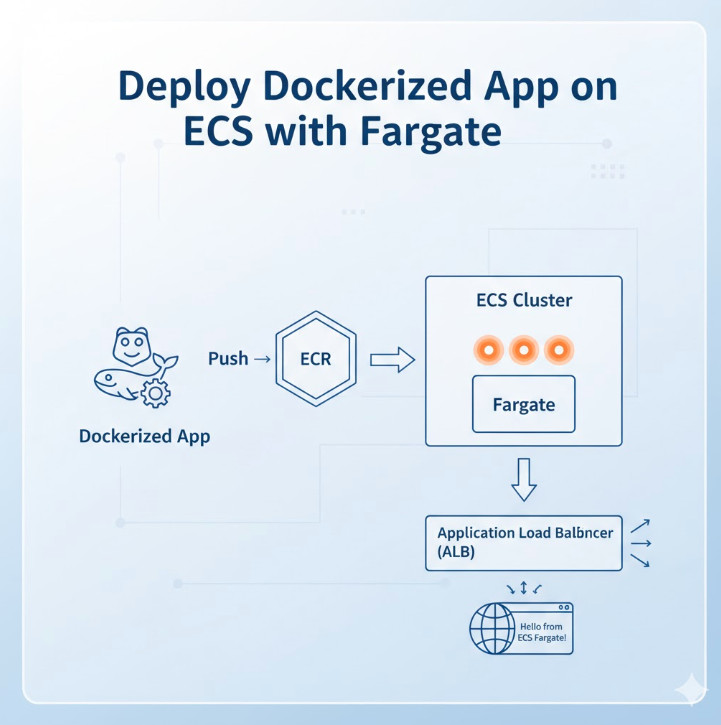
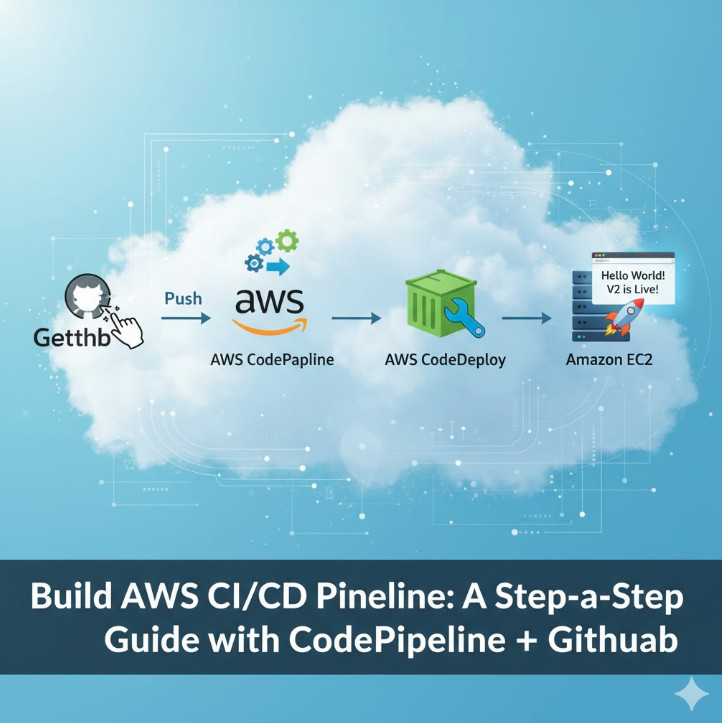
Welcome to the definitive guide on using Terraform to provision and manage Amazon Elastic Kubernetes Service (EKS). Manually setting up a Kubernetes cluster on AWS involves navigating a complex web of resources: VPCs, subnets, IAM roles, security groups, and the EKS control plane itself. This process is not only time-consuming but also prone to human error and difficult to reproduce.
This is where Terraform, the industry-standard Infrastructure as Code (IaC) tool, becomes indispensable. By defining your infrastructure in declarative configuration files, you can automate the entire provisioning process, ensuring consistency, repeatability, and version control. In this comprehensive tutorial, we will walk you through every step required to deploy an EKS cluster using Terraform, from setting up the networking to configuring node groups and connecting with kubectl. This guide is designed for DevOps engineers, SREs, and system administrators looking to adopt best practices for their Kubernetes cluster on AWS.
Why Use Terraform to Deploy an EKS Cluster?
While the AWS Management Console or AWS CLI are valid ways to start, any production-grade system benefits immensely from an IaC approach. When you deploy an EKS cluster, you’re not just creating one resource; you’re orchestrating dozens of interconnected components. Terraform excels at managing this complexity.
The Power of Infrastructure as Code (IaC)
Infrastructure as Code (IaC) is the practice of managing and provisioning infrastructure through machine-readable definition files, rather than physical hardware configuration or interactive configuration tools. Terraform allows you to write, plan, and create your AWS EKS cluster setup with code. This code can be versioned in Git, peer-reviewed, and tested, just like your application code.
Repeatability and Consistency
Need to spin up an identical cluster for staging, development, or a different region? With a manual process, this is a nightmare of forgotten settings and configuration drift. With Terraform, you simply run terraform apply. Your configuration files are the single source of truth, guaranteeing that every environment is a precise, consistent replica.
State Management and Version Control
Terraform creates a state file that maps your configuration to the real-world resources it has created. This state allows Terraform to plan changes, understand dependencies, and manage the entire lifecycle of your infrastructure. When you need to upgrade your EKS version or change a node’s instance type, Terraform calculates the exact changes needed and executes them in the correct order. You can destroy the entire stack with a single terraform destroy command, ensuring no orphaned resources are left behind.
Prerequisites: What You Need Before You Start
Before we begin, ensure you have the following tools and accounts set up. This guide assumes you are comfortable working from the command line.
- An AWS Account: You will need an AWS account with IAM permissions to create EKS clusters, VPCs, IAM roles, and associated resources.
- AWS CLI: The AWS Command Line Interface, configured with your credentials (e.g., via
aws configure). - Terraform: Terraform (version 1.0.0 or later) installed on your local machine.
kubectl: The Kubernetes command-line tool. This is used to interact with your cluster once it’s created.aws-iam-authenticator(Optional but Recommended): This helper binary allowskubectlto use AWS IAM credentials for authentication. However, modern AWS CLI versions (1.16.156+) can handle this natively with theaws eks update-kubeconfigcommand, which we will use.
Step-by-Step Guide: Provisioning Your EKS Infrastructure
We will build our configuration using the official, battle-tested Terraform EKS module. This module abstracts away immense complexity and encapsulates best practices for EKS cluster provisioning.
Step 1: Setting Up Your Terraform Project
First, create a new directory for your project. Inside this directory, we’ll create several .tf files to keep our configuration organized.
Your directory structure will look like this:
.
├── main.tf
├── variables.tf
└── outputs.tf
Let’s start with main.tf. This file will contain our provider configuration and the module calls.
# main.tf
terraform {
required_version = "~> 1.5"
required_providers {
aws = {
source = "hashicorp/aws"
version = "~> 5.0"
}
}
}
provider "aws" {
region = var.aws_region
}
# Define a random string to ensure unique EKS cluster names
resource "random_pet" "cluster_name_suffix" {
length = 2
}
Next, define your variables in variables.tf. This allows you to easily customize your deployment without changing the core logic.
# variables.tf
variable "aws_region" {
description = "The AWS region to deploy resources in."
type = string
default = "us-east-1"
}
variable "cluster_name" {
description = "The name for your EKS cluster."
type = string
default = "my-demo-cluster"
}
variable "cluster_version" {
description = "The Kubernetes version for the EKS cluster."
type = string
default = "1.29"
}
variable "vpc_cidr" {
description = "The CIDR block for the EKS cluster VPC."
type = string
default = "10.0.0.0/16"
}
variable "azs" {
description = "Availability Zones for the VPC and EKS."
type = list(string)
default = ["us-east-1a", "us-east-1b", "us-east-1c"]
}
Step 2: Defining the Networking (VPC)
An EKS cluster requires a robust, highly available Virtual Private Cloud (VPC) with both public and private subnets across multiple Availability Zones. We will use the official Terraform VPC module to handle this.
Add the following to your main.tf file:
# main.tf (continued...)
module "vpc" {
source = "terraform-aws-modules/vpc/aws"
version = "5.5.3"
name = "${var.cluster_name}-vpc"
cidr = var.vpc_cidr
azs = var.azs
private_subnets = [for k, v in var.azs : cidrsubnet(var.vpc_cidr, 8, k + 4)]
public_subnets = [for k, v in var.azs : cidrsubnet(var.vpc_cidr, 8, k)]
enable_nat_gateway = true
single_nat_gateway = true
enable_dns_hostnames = true
# Tags required by EKS
public_subnet_tags = {
"kubernetes.io/cluster/${var.cluster_name}-${random_pet.cluster_name_suffix.id}" = "shared"
"kubernetes.io/role/elb" = "1"
}
private_subnet_tags = {
"kubernetes.io/cluster/${var.cluster_name}-${random_pet.cluster_name_suffix.id}" = "shared"
"kubernetes.io/role/internal-elb" = "1"
}
}
This block provisions a new VPC with public subnets (for load balancers) and private subnets (for worker nodes) across the three AZs we defined. Crucially, it adds the specific tags that EKS requires to identify which subnets it can use for internal and external load balancers.
Step 3: Defining the EKS Cluster with the Official Module
Now for the main event. We will add the terraform-aws-modules/eks/aws module. This single module will create:
- The EKS Control Plane
- The necessary IAM Roles (for the cluster and nodes)
- Security Groups
- Managed Node Groups
Add this final block to your main.tf:
# main.tf (continued...)
module "eks" {
source = "terraform-aws-modules/eks/aws"
version = "20.8.4"
cluster_name = "${var.cluster_name}-${random_pet.cluster_name_suffix.id}"
cluster_version = var.cluster_version
cluster_endpoint_public_access = true
vpc_id = module.vpc.vpc_id
subnet_ids = module.vpc.private_subnets
# EKS Managed Node Group configuration
eks_managed_node_groups = {
general_purpose = {
name = "general-purpose-nodes"
instance_types = ["t3.medium"]
min_size = 1
max_size = 3
desired_size = 2
# Use the private subnets
subnet_ids = module.vpc.private_subnets
tags = {
Purpose = "general-purpose-workloads"
}
}
}
# This allows our local kubectl to authenticate
# by mapping the default AWS user/role that runs terraform
# to the "system:masters" group in Kubernetes RBAC.
aws_auth_roles = [
{
rolearn = "arn:aws:iam::${data.aws_caller_identity.current.account_id}:role/AWSServiceRoleForAmazonEKS"
username = "system:node:{{EC2PrivateDNSName}}"
groups = [
"system:bootstrappers",
"system:nodes",
]
}
]
aws_auth_users = [
{
userarn = data.aws_caller_identity.current.arn
username = "admin"
groups = [
"system:masters"
]
}
]
}
data "aws_caller_identity" "current" {}
This configuration defines an EKS cluster and a managed node group named general_purpose. This node group will run t3.medium instances and will auto-scale between 1 and 3 nodes, starting with 2. The aws_auth_users block is critical: it takes the IAM identity (user or role) that is running Terraform and grants it system:masters (admin) permissions within the new Kubernetes cluster.
Step 4: Defining Outputs
Finally, we need to output the cluster’s information so we can connect to it. Create an outputs.tf file.
# outputs.tf
output "cluster_name" {
description = "The name of the EKS cluster."
value = module.eks.cluster_name
}
output "cluster_endpoint" {
description = "The endpoint for your EKS cluster."
value = module.eks.cluster_endpoint
}
output "cluster_ca_certificate" {
description = "Base64 encoded certificate data for cluster."
value = module.eks.cluster_certificate_authority_data
}
output "configure_kubectl_command" {
description = "Command to configure kubectl to connect to the cluster."
value = "aws eks update-kubeconfig --region ${var.aws_region} --name ${module.eks.cluster_name}"
}
Step 5: Deploying and Connecting to Your Cluster
With all our configuration files in place, it’s time to deploy.
Initialize and Apply
Run the following commands in your terminal:
# 1. Initialize the Terraform project
# This downloads the AWS provider and the EKS/VPC modules
terraform init
# 2. Plan the deployment
# This shows you all the resources Terraform will create
terraform plan
# 3. Apply the configuration
# This will build the VPC, IAM roles, and EKS cluster.
# It can take 15-20 minutes for the EKS cluster to become active.
terraform apply --auto-approve
After terraform apply completes, it will print the values from your outputs.tf file.
Configuring kubectl
The easiest way to configure your local kubectl is to use the command we generated in our outputs. Copy the value of configure_kubectl_command from the Terraform output and paste it into your terminal.
# This command will be printed by 'terraform apply'
aws eks update-kubeconfig --region us-east-1 --name my-demo-cluster-xy
This AWS CLI command automatically updates your local ~/.kube/config file with the new cluster’s credentials and endpoint.
Verifying the Cluster
You can now use kubectl to interact with your cluster. Let’s check the status of our nodes:
kubectl get nodes
# You should see an output similar to this, showing your 2 nodes are 'Ready':
# NAME STATUS ROLES AGE VERSION
# ip-10-0-10-123.ec2.internal Ready 5m v1.29.0-eks
# ip-10-0-11-45.ec2.internal Ready 5m v1.29.0-eks
You can also check the pods running in the kube-system namespace:
kubectl get pods -n kube-system
# You will see core components like coredns and the aws-node (VPC CNI) pods.
Congratulations! You have successfully deployed a production-ready EKS cluster using Terraform.
Advanced Considerations and Best Practices
This guide provides a strong foundation, but a true production environment has more components. Here are key areas to explore next:
- IAM Roles for Service Accounts (IRSA): Instead of giving broad permissions to worker nodes, use IRSA to assign fine-grained IAM roles directly to your Kubernetes service accounts. This is the most secure way for your pods (e.g.,
external-dns,aws-load-balancer-controller) to interact with AWS APIs. The Terraform EKS module has built-in support for this. - Cluster Autoscaling: We configured the Managed Node Group to scale, but for more advanced scaling based on pod resource requests, you should deploy the Kubernetes Cluster Autoscaler.
- EKS Add-ons: EKS manages core add-ons like
vpc-cni,kube-proxy, andcoredns. You can manage the versions of these add-ons directly within the Terraform EKS module block, treating them as code as well. - Logging and Monitoring: Configure EKS control plane logging (api, audit, authenticator) and ship those logs to CloudWatch. Use the EKS module to enable these logs and deploy monitoring solutions like Prometheus and Grafana.
Frequently Asked Questions
- Can I use this guide to deploy an EKS cluster into an existing VPC?
- Yes. Instead of using the
module "vpc", you would remove that block and pass your existing VPC and subnet IDs directly to themodule "eks"block’svpc_idandsubnet_idsarguments. You must ensure your subnets are tagged correctly as described in Step 2. - How do I upgrade my EKS cluster’s Kubernetes version using Terraform?
- It’s a two-step process. First, update the
cluster_versionargument in yourvariables.tf(e.g., from “1.29” to “1.30”). Runterraform applyto upgrade the control plane. Once that is complete, you must also upgrade your node groups by updating their version (or by default, they will upgrade on the next AMI rotation if configured). - What is the difference between Managed Node Groups and Fargate?
- Managed Node Groups (used in this guide) provision EC2 instances that you manage (but AWS patches). You have full control over the instance type and operating system. AWS Fargate is a serverless compute engine that allows you to run pods without managing any underlying EC2 instances at all. The EKS module also supports creating Fargate profiles.


Conclusion
You have now mastered the fundamentals of EKS cluster provisioning with Infrastructure as Code. By leveraging the official Terraform EKS module, you’ve abstracted away massive complexity and built a scalable, repeatable, and maintainable foundation for your Kubernetes workloads on AWS. This declarative approach is the cornerstone of modern DevOps and SRE practices, enabling you to manage infrastructure with the same rigor and confidence as application code.
By following this guide, you’ve learned not just how to deploy EKS cluster infrastructure, but how to do it in a way that is robust, scalable, and manageable. From here, you are well-equipped to explore advanced topics like IRSA, cluster autoscaling, and CI/CD pipelines for your new Kubernetes cluster. Thank you for reading the DevopsRoles page!