Discover the revolutionary way to enhance your network security by integrating Tailscale in Docker containers on Linux. This comprehensive guide will walk you through the essential steps needed to set up Tailscale, ensuring your containerized applications remain secure and interconnected. Dive into the world of seamless networking today!
Table of Contents
Introduction to Tailscale in Docker Containers
In the dynamic world of technology, ensuring robust network security and seamless connectivity has become paramount. Enter Tailscale, a user-friendly, secure network mesh that leverages WireGuard’s noise protocol. When combined with Docker, a leading software containerization platform, Tailscale empowers Linux users to secure and streamline their network connections effortlessly. This guide will unveil how to leverage Tailscale within Docker containers on Linux, paving the way for enhanced security and simplified connectivity.
Preparing Your Linux Environment
Before diving into the world of Docker and Tailscale, it’s essential to prepare your Linux environment. Begin by ensuring your system is up-to-date:
sudo apt-get update && sudo apt-get upgradeNext, install Docker on your Linux machine if you haven’t already:
sudo apt-get install docker.ioOnce Docker is installed, start the Docker service and enable it to launch at boot:
sudo systemctl start docker && sudo systemctl enable dockerEnsure your user is added to the Docker group to avoid using sudo for Docker commands:
sudo usermod -aG docker ${USER}Log out and back in for this change to take effect, or if you’re in a terminal, type newgrp docker.
Setting Up Tailscale in Docker Containers
Now, let’s set up Tailscale within a Docker container. Create a Dockerfile to build your Tailscale container:
FROM alpine:latest
RUN apk --no-cache add tailscale
COPY entrypoint.sh /entrypoint.sh
RUN chmod +x /entrypoint.sh
ENTRYPOINT ["/entrypoint.sh"]In your entrypoint.sh, include the Tailscale startup commands:
#!/bin/sh
tailscale up --advertise-routes=10.0.0.0/24 --accept-routesBuild and run your Docker container:
docker build -t tailscale . docker run --name=mytailscale --privileged -d tailscaleThe --privileged flag is essential for Tailscale to modify the network interfaces within the container.
Verifying Connectivity and Security
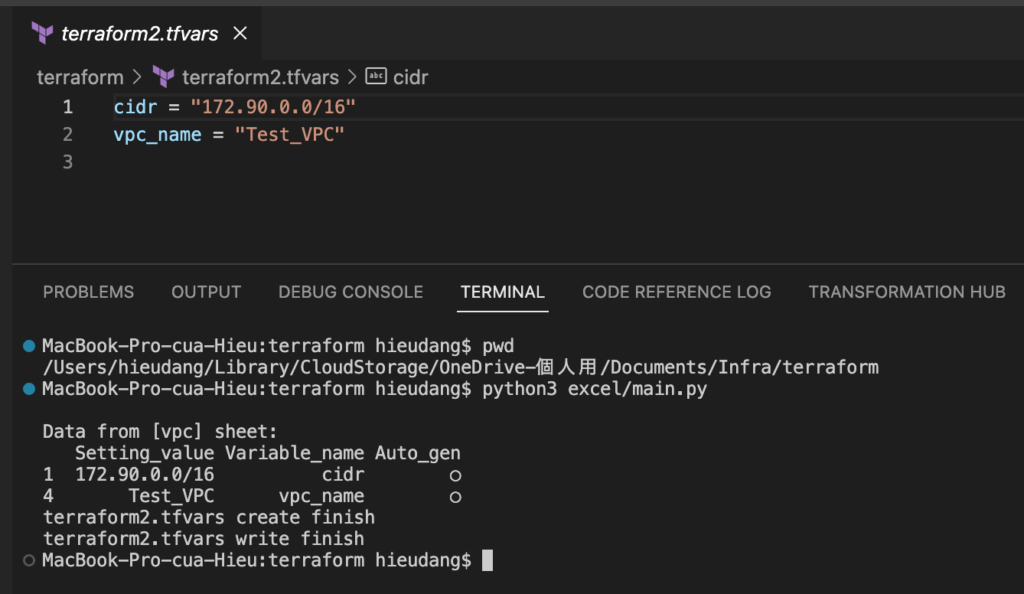
After setting up Tailscale in your Docker container, it’s crucial to verify connectivity and ensure your network is secure. Check the Tailscale interface and connectivity:
docker exec mytailscale tailscale statusThis command provides details on your Tailscale network, including the connected devices. Test the security and functionality by accessing services across your Tailscale network, ensuring that all traffic is encrypted and routes correctly.
Tips and Best Practices
To maximize the benefits of Tailscale in Docker containers on Linux, consider the following tips and best practices:
- Regularly update your Tailscale and Docker packages to benefit from the latest features and security improvements.
- Explore Tailscale’s ACLs (Access Control Lists) to fine-tune which devices and services can communicate across your network.
- Consider using Docker Compose to manage Tailscale containers alongside your other Dockerized services for ease of use and automation.
I hope will this your helpful. Thank you for reading the DevopsRoles page!