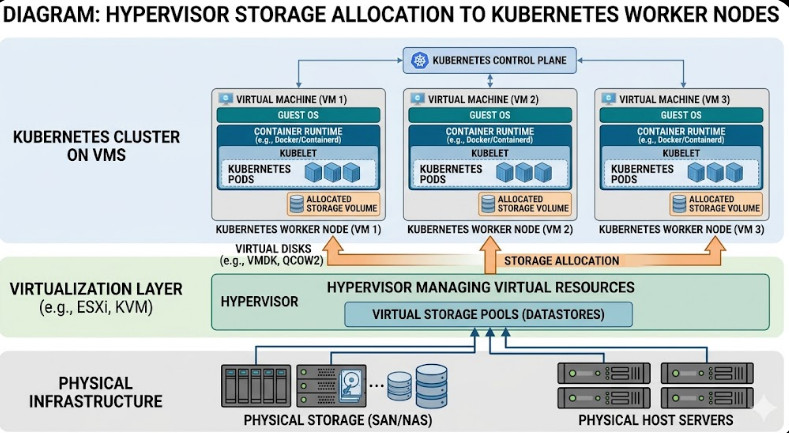
In the current landscape of generative AI, reliance on massive, public cloud APIs introduces significant latency, cost volatility, and critical data sovereignty risks. For organizations handling sensitive data—such as financial records, proprietary research, or HIPAA-protected patient data—the necessity of a localized, self-contained infrastructure is paramount.
The goal is no longer simply running a model; it is building a resilient, scalable, and secure private cloud ai assistants platform. This architecture must function as a complete, isolated ecosystem, capable of hosting multiple specialized AI services (LLMs, image generators, data processors) on dedicated, on-premise hardware.
This deep-dive guide moves beyond basic tutorials. We will architect a production-grade, multi-tenant private cloud ai assistants solution, focusing heavily on container orchestration, network segmentation, and enterprise-grade security practices suitable for Senior DevOps and MLOps engineers.
Phase 1: Core Architecture and Conceptual Design
Building a self-hosted AI platform requires treating the entire stack—from the physical server to the deployed model—as a single, cohesive, and highly optimized system. We are not just installing software; we are defining a resilient compute fabric.
The Stack Components
Our target architecture is a layered, microservices-based system.
- Base Layer (Infrastructure): This involves the physical hardware (bare metal servers) and the foundational OS (e.g., Ubuntu LTS or RHEL). Hardware acceleration (GPUs, specialized NPUs) is non-negotiable for efficient AI inference.
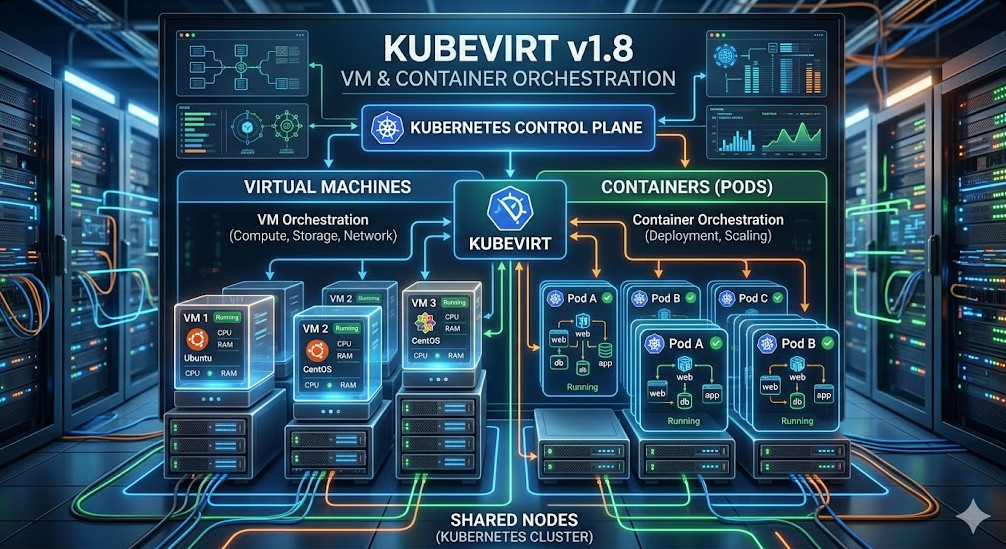
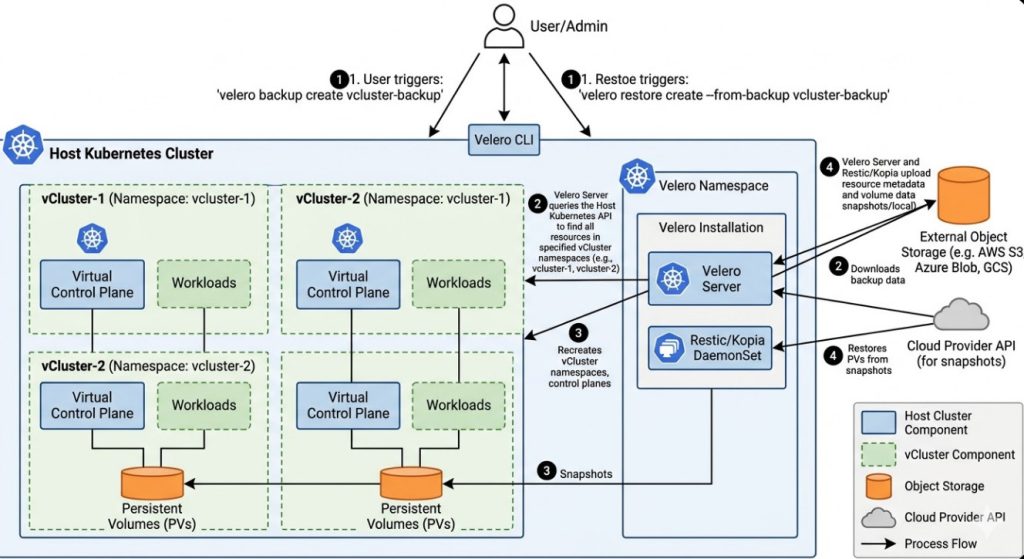
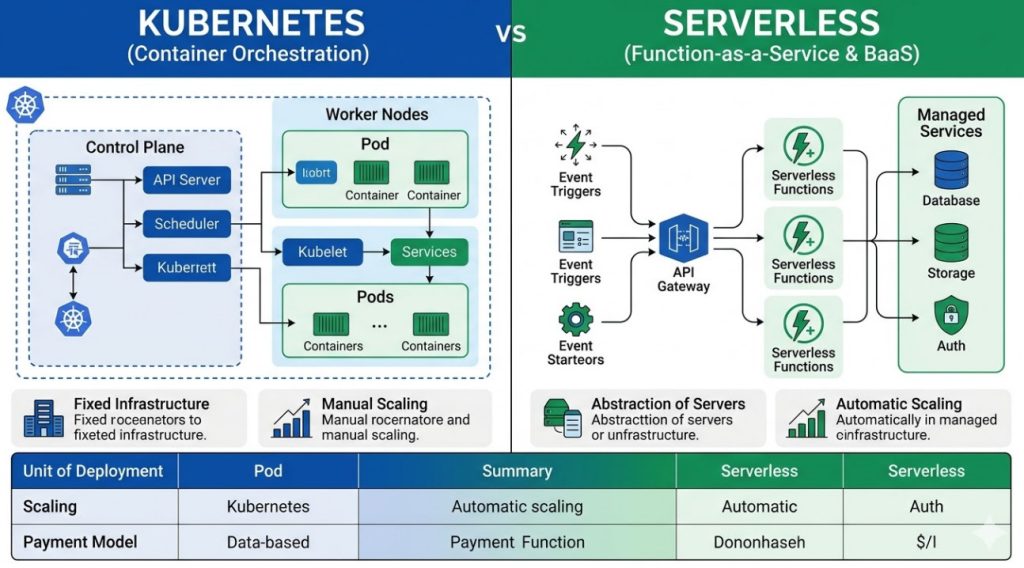
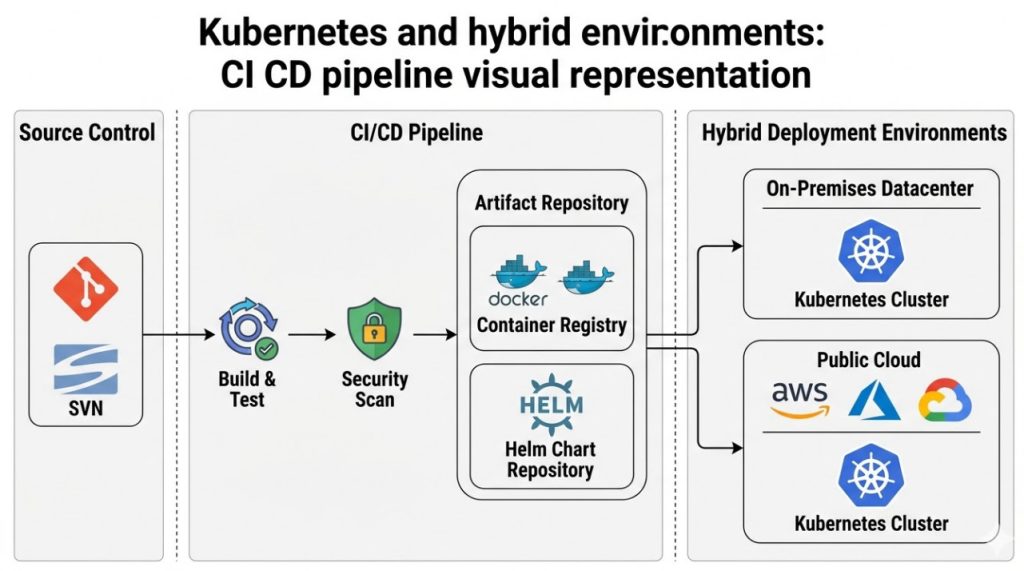
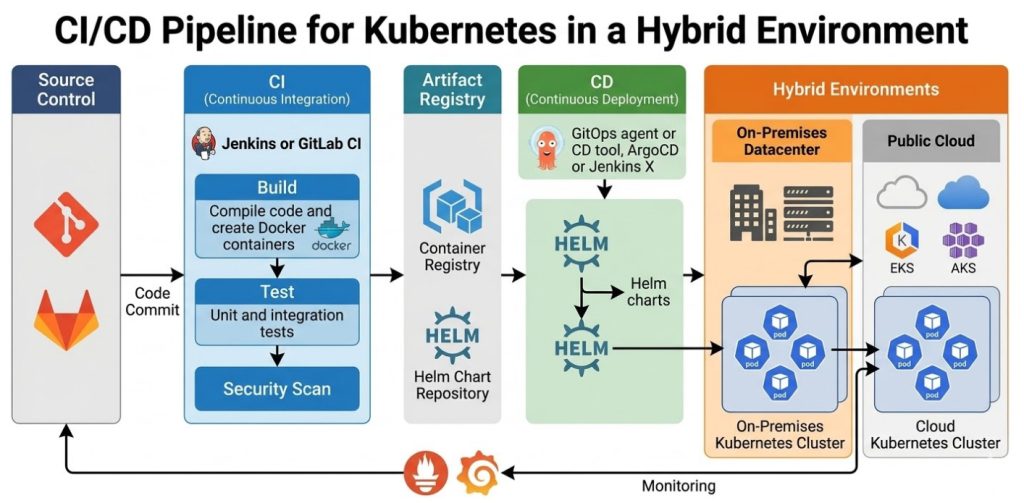
- Containerization Layer (Isolation): We utilize Docker for packaging and Kubernetes (K8s) for orchestration. K8s provides the necessary primitives for service discovery, self-healing, and resource management across multiple nodes.
- Networking Layer (Security & Routing): A robust Service Mesh (like Istio or Linkerd) is critical. It handles secure, mutual TLS (mTLS) communication between the various AI microservices, ensuring that traffic is encrypted and authenticated at the application layer.
- AI/MLOps Layer (The Brain): This is where the intelligence resides. We deploy specialized inference servers, such as NVIDIA Triton Inference Server, to manage multiple models (LLMs, computer vision models) efficiently. This layer must support model versioning and A/B testing.
Architectural Deep Dive: Resource Management
The biggest challenge in a multi-tenant private cloud ai assistants setup is resource contention. If one assistant (e.g., a large language model inference) spikes its GPU utilization, it must not starve the other services (e.g., a simple data validation microservice).
To solve this, we implement Resource Quotas and Limit Ranges within Kubernetes. These parameters define hard boundaries on CPU, memory, and GPU access for every deployed workload. This prevents noisy neighbor problems and ensures predictable performance, which is crucial for maintaining Service Level Objectives (SLOs).


Phase 2: Practical Implementation Walkthrough (Hands-On)
This phase details the practical steps to bring the architecture to life, assuming a minimum of two GPU-enabled nodes and a stable network backbone.
Step 2.1: Establishing the Kubernetes Cluster
First, we provision the cluster using kubeadm or a managed tool like Rancher. Crucially, we must ensure the GPU drivers and the Container Runtime Interface (CRI) are correctly configured to expose GPU resources to K8s.
For GPU visibility, you must install the appropriate device plugin (e.g., the NVIDIA device plugin) into the cluster. This allows K8s to treat GPU memory and compute units as schedulable resources.
Step 2.2: Deploying the AI Assistants via Helm
We will use Helm Charts to manage the deployment of our four distinct assistants (e.g., LLM Chatbot, Code Generator, Image Processor, Data Validator). Helm allows us to parameterize the deployment, making the setup repeatable and idempotent.
The deployment manifest must specify resource requests and limits for each assistant.
Code Block 1: Example Kubernetes Deployment Manifest (Deployment YAML)
apiVersion: apps/v1
kind: Deployment
metadata:
name: llm-assistant-deployment
labels:
app: ai-assistant
spec:
replicas: 2
selector:
matchLabels:
app: llm-assistant
template:
metadata:
labels:
app: ai-assistant
spec:
containers:
- name: llm-container
image: your-private-registry/llm-service:v1.2.0
resources:
limits:
nvidia.com/gpu: 1 # Requesting 1 dedicated GPU
memory: "16Gi"
cpu: "4"
requests:
nvidia.com/gpu: 1
memory: "8Gi"
cpu: "2"
ports:
- containerPort: 8080
Step 2.3: Configuring the Service Mesh for Inter-Service Communication
Once the assistants are running, we must secure their communication. Deploying a Service Mesh (e.g., Istio) automatically handles mTLS encryption between services. This means that even if an attacker gains network access, the communication between the Code Generator and the Data Validator remains encrypted and authenticated.
This step is vital for meeting strict compliance requirements and is a key differentiator between a simple container setup and a true enterprise private cloud ai assistants platform.
💡 Pro Tip: When designing the service mesh, do not rely solely on default ingress rules. Implement Authorization Policies that enforce the principle of least privilege. For example, the Image Processor should only be allowed to communicate with the central Identity Service, and nothing else.
Phase 3: Senior-Level Best Practices, Security, and Scaling
A successful deployment is only the beginning. Sustaining a high-performance, secure private cloud ai assistants platform requires continuous optimization and rigorous security hardening.
SecOps Deep Dive: Hardening the Platform
Security must be baked into every layer, not bolted on afterward.
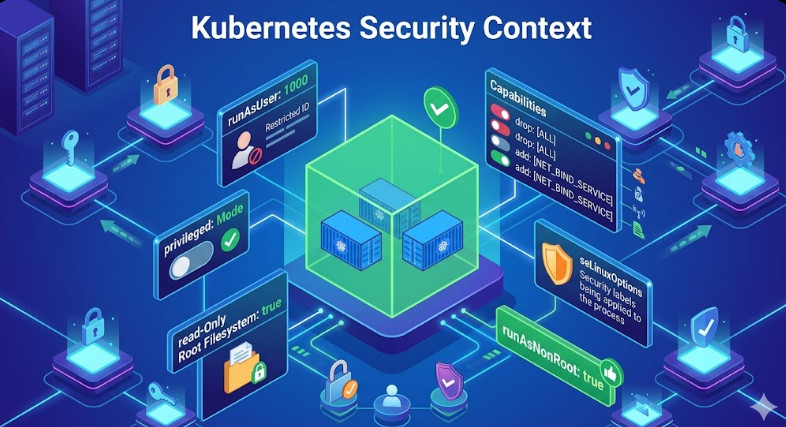
- Network Segmentation: Use Network Policies (a native K8s feature) to enforce strict L3/L4 firewall rules between namespaces. The LLM namespace should be logically separated from the Billing/Auth namespace.
- Secrets Management: Never store credentials in environment variables or YAML files. Utilize dedicated secret managers like HashiCorp Vault or Kubernetes Secrets backed by an external KMS (Key Management Service).
- Runtime Security: Implement tools like Falco to monitor container runtime activity. Falco can detect anomalous behavior, such as a container attempting to execute shell commands or write to sensitive system directories.
MLOps Optimization: Model Lifecycle Management
The operational efficiency of the AI assistants depends on how we manage the models themselves.
- Model Registry: Use a dedicated Model Registry (e.g., MLflow) to version and track every model artifact.
- Canary Deployments: When updating an assistant, never deploy the new version to 100% of traffic immediately. Use K8s/Istio to route a small percentage (e.g., 5%) of live traffic to the new version. Monitor key metrics (latency, error rate) before rolling out fully.
- Quantization and Pruning: Before deployment, optimize the models. Techniques like quantization (reducing floating-point precision from FP32 to INT8) can drastically reduce model size and memory footprint with minimal performance loss, improving overall GPU utilization.
Code Block 2: Example Kubernetes Network Policy (Security)
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: restrict-llm-traffic
namespace: ai-assistants
spec:
podSelector:
matchLabels:
app: llm-assistant
policyTypes:
- Ingress
- Egress
ingress:
- from:
- podSelector:
matchLabels:
app: api-gateway # Only allow traffic from the API Gateway
ports:
- port: 8080
protocol: TCP
egress:
- to:
- ipBlock:
cidr: 10.0.0.0/8 # Only allow egress to internal services
ports:
- port: 9090
protocol: TCP
Scaling and Observability
A robust private cloud ai assistants platform requires comprehensive observability. We must monitor not just CPU/RAM, but specialized metrics like GPU utilization percentage, VRAM temperature, and inference latency.
Integrate Prometheus and Grafana to scrape these metrics. Set up alerts that trigger when resource utilization exceeds defined thresholds or when the error rate for a specific assistant spikes above 0.5%.
For a deeper dive into the operational roles required to maintain this complex environment, check out the comprehensive guide on DevOps roles.
Conclusion: The Future of Edge AI
Building a self-contained private cloud ai assistants ecosystem is a significant undertaking, but the control, security, and cost predictability it offers are invaluable. By mastering container orchestration, service mesh implementation, and MLOps best practices, organizations can move beyond API dependence and truly own their AI infrastructure.
If you are looking to replicate or learn more about the foundational architecture of such a system, we recommend reviewing the detailed project walkthrough here: i built a private cloud with 4 ai assistants on one server.