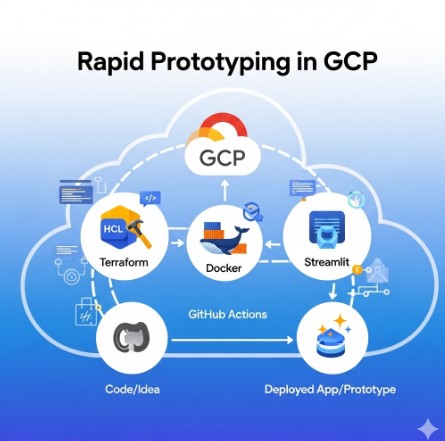
In today’s fast-paced development environment, the ability to rapidly prototype and iterate on cloud-based applications is crucial. This article focuses on rapid prototyping GCP, demonstrating how to leverage the power of Google Cloud Platform (GCP) in conjunction with Terraform, Docker, GitHub Actions, and Streamlit to significantly reduce development time and streamline the prototyping process. We’ll explore a robust, repeatable workflow that empowers developers to quickly test, validate, and iterate on their ideas, ultimately leading to faster time-to-market and improved product quality.
Setting Up Your Infrastructure with Terraform
Terraform is an Infrastructure as Code (IaC) tool that allows you to define and manage your GCP infrastructure in a declarative manner. This means you describe the desired state of your infrastructure in a configuration file, and Terraform handles the provisioning and management.
Defining Your GCP Resources
A typical Terraform configuration for rapid prototyping GCP might include resources such as:
- Compute Engine virtual machines (VMs): Define the specifications of your VMs, including machine type, operating system, and boot disk.
- Cloud Storage buckets: Create storage buckets to store your application code, data, and dependencies.
- Cloud SQL instances: Provision database instances if your application requires a database.
- Virtual Private Cloud (VPC) networks: Configure your VPC network, subnets, and firewall rules to secure your environment.
Example Terraform Code
Here’s a simplified example of a Terraform configuration to create a Compute Engine VM:
resource "google_compute_instance" "default" {
name = "prototype-vm"
machine_type = "e2-medium"
zone = "us-central1-a"
boot_disk {
initialize_params {
image = "debian-cloud/debian-9"
}
}
}Containerizing Your Application with Docker
Docker is a containerization technology that packages your application and its dependencies into a single, portable unit. This ensures consistency across different environments, making it ideal for rapid prototyping GCP.
Creating a Dockerfile
A Dockerfile outlines the steps to build your Docker image. It specifies the base image, copies your application code, installs dependencies, and defines the command to run your application.
Example Dockerfile
FROM python:3.9-slim-buster
WORKDIR /app
COPY requirements.txt requirements.txt
RUN pip install --no-cache-dir -r requirements.txt
COPY . .
CMD ["streamlit", "run", "app.py"]Automating Your Workflow with GitHub Actions
GitHub Actions allows you to automate your development workflow, including building, testing, and deploying your application. This is essential for rapid prototyping GCP, enabling continuous integration and continuous deployment (CI/CD).
Creating a GitHub Actions Workflow
A GitHub Actions workflow typically involves the following steps:
- Trigger: Define the events that trigger the workflow, such as pushing code to a repository branch.
- Build: Build your Docker image using the Dockerfile.
- Test: Run unit and integration tests to ensure the quality of your code.
- Deploy: Deploy your Docker image to GCP using tools like `gcloud` or a container registry.
Example GitHub Actions Workflow (YAML)
name: Deploy to GCP
on:
push:
branches:
- main
jobs:
deploy:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Build Docker Image
run: docker build -t my-app:latest .
- name: Login to Google Cloud Container Registry
run: gcloud auth configure-docker
- name: Push Docker Image
run: docker push gcr.io/$PROJECT_ID/my-app:latest
- name: Deploy to GCP
run: gcloud compute instances create my-instance --zone=us-central1-a --machine-type=e2-medium --image=gcr.io/$PROJECT_ID/my-app:latestBuilding Interactive Prototypes with Streamlit
Streamlit is a Python library that simplifies the creation of interactive web applications. Its ease of use makes it perfectly suited for rapid prototyping GCP, allowing you to quickly build user interfaces to visualize data and interact with your application.
Creating a Streamlit App
A simple Streamlit app might look like this:
import streamlit as st
st.title("My GCP Prototype")
st.write("This is a simple Streamlit app running on GCP.")
name = st.text_input("Enter your name:")
if name:
st.write(f"Hello, {name}!")Rapid Prototyping GCP: A Complete Workflow
Combining these technologies creates a powerful workflow for rapid prototyping GCP:
- Develop your application code.
- Create a Dockerfile to containerize your application.
- Write Terraform configurations to define your GCP infrastructure.
- Set up a GitHub Actions workflow to automate the build, test, and deployment processes.
- Use Streamlit to build an interactive prototype to test and showcase your application.
This iterative process allows for quick feedback loops, enabling you to rapidly iterate on your designs and incorporate user feedback.
Frequently Asked Questions
Q1: What are the benefits of using Terraform for infrastructure management in rapid prototyping?
A1: Terraform provides a declarative approach, ensuring consistency and reproducibility. It simplifies infrastructure setup and teardown, making it easy to spin up and down environments quickly, ideal for the iterative nature of prototyping. This reduces manual configuration errors and speeds up the entire development lifecycle.
Q2: How does Docker improve the efficiency of rapid prototyping in GCP?
A2: Docker ensures consistent environments across different stages of development and deployment. By packaging the application and dependencies, Docker eliminates environment-specific issues that often hinder prototyping. It simplifies deployment to GCP by utilizing container registries and managed services.
Q3: Can I use other CI/CD tools besides GitHub Actions for rapid prototyping on GCP?
A3: Yes, other CI/CD platforms like Cloud Build, Jenkins, or GitLab CI can be integrated with GCP. The choice depends on your existing tooling and preferences. Each offers similar capabilities for automated building, testing, and deployment.
Q4: What are some alternatives to Streamlit for building quick prototypes?
A4: While Streamlit is excellent for rapid development, other options include frameworks like Flask or Django (for more complex applications), or even simpler tools like Jupyter Notebooks for data exploration and visualization within the prototype.

Conclusion
This article demonstrated how to effectively utilize Terraform, Docker, GitHub Actions, and Streamlit to significantly enhance your rapid prototyping GCP capabilities. By adopting this workflow, you can drastically reduce development time, improve collaboration, and focus on iterating and refining your applications. Remember that continuous integration and continuous deployment are key to maximizing the efficiency of your rapid prototyping GCP strategy. Mastering these tools empowers you to rapidly test ideas, validate concepts, and bring innovative cloud solutions to market with unparalleled speed.
For more detailed information on Terraform, consult the official documentation: https://www.terraform.io/docs/index.html
For more on Docker, see: https://docs.docker.com/
For further details on GCP deployment options, refer to: https://cloud.google.com/docs. Thank you for reading the DevopsRoles page!