Table of Contents
#Introduction
In this tutorial, How to deploy OpenProject platform as a Docker Container.
OpenProject is an outstanding platform for project management. It is manage meetings, control project budgets, run reports on your projects, communicate with a project team, etc.
Deploy OpenProject platform as a Docker Container
Install Docker and Docker-Compose
I will this deployment on Ubuntu Server.
sudo apt-get install docker.io -y
sudo usermod -aG docker $USER
sudo curl -L "https://github.com/docker/compose/releases/download/1.23.1/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
sudo chmod +x /usr/local/bin/docker-composeCheck version after finished install.
root@DevopsRoles:~# docker --version
Docker version 20.10.2, build 20.10.2-0ubuntu2
root@DevopsRoles:~# docker-compose --version
docker-compose version 1.23.1, build b02f1306Deploy OpenProject with Docker Compose
git clone https://github.com/opf/openproject-deploy --depth=1 --branch=stable/11 myopenproject
cd myopenproject/compose
docker-compose pull # Make sure to update docker images.
docker-compose up -d # You need to wait a few minutes.For example, The output terminal is as below:
root@DevopsRoles:~# git clone https://github.com/opf/openproject-deploy --depth=1 --branch=stable/11 myopenproject
Cloning into 'myopenproject'...
remote: Enumerating objects: 7, done.
remote: Counting objects: 100% (7/7), done.
remote: Compressing objects: 100% (6/6), done.
remote: Total 7 (delta 0), reused 2 (delta 0), pack-reused 0
Receiving objects: 100% (7/7), done.
root@DevopsRoles:~# cd myopenproject/compose
root@DevopsRoles:~/myopenproject/compose# docker-compose pull
Pulling db ... done
Pulling cache ... done
Pulling seeder ... done
Pulling cron ... done
Pulling worker ... done
Pulling web ... done
Pulling proxy ... done
root@DevopsRoles:~/myopenproject/compose# docker-compose up -d
Creating network "compose_backend" with the default driver
Creating network "compose_frontend" with the default driver
Creating volume "compose_pgdata" with default driver
Creating volume "compose_opdata" with default driver
Creating compose_seeder_1_f0f0cb90c947 ... done
Creating compose_cache_1_e6fe61ccd342 ... done
Creating compose_db_1_17392590a82e ... done
Creating compose_cron_1_f15f9d68fc11 ... done
Creating compose_web_1_ce68c823fc5f ... done
Creating compose_worker_1_a9c88ca2f672 ... done
Creating compose_proxy_1_c7c5f08e77e8 ... done
root@DevopsRoles:~/myopenproject/compose#
root@DevopsRoles:~/myopenproject/compose# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
9aa1fe05f737 openproject/community:11 "./docker/prod/entry…" 40 seconds ago Up 35 seconds 5432/tcp, 0.0.0.0:8080->80/tcp compose_proxy_1_5fdbbaa63ec5
2df1b233a515 openproject/community:11 "./docker/prod/entry…" 42 seconds ago Up 39 seconds 80/tcp, 5432/tcp compose_worker_1_6db9f1adb68b
e1b6878e9e32 openproject/community:11 "./docker/prod/entry…" 42 seconds ago Up 39 seconds 80/tcp, 5432/tcp compose_web_1_544e288b78ff
ef3b645bc783 openproject/community:11 "./docker/prod/entry…" 42 seconds ago Up 39 seconds 80/tcp, 5432/tcp compose_cron_1_db11c0e207d9
0dad3d1c28d1 postgres:10 "docker-entrypoint.s…" 46 seconds ago Up 41 seconds 5432/tcp compose_db_1_31484339d5bc
1cd386cca514 memcached "docker-entrypoint.s…" 46 seconds ago Up 41 seconds 11211/tcp compose_cache_1_6b9f381e6e82
13f9ad2a8cfa openproject/community:11 "./docker/prod/entry…" 46 seconds ago Up 41 seconds 80/tcp, 5432/tcp compose_seeder_1_f88dde804cb4
The result is openproject docker the picture below:

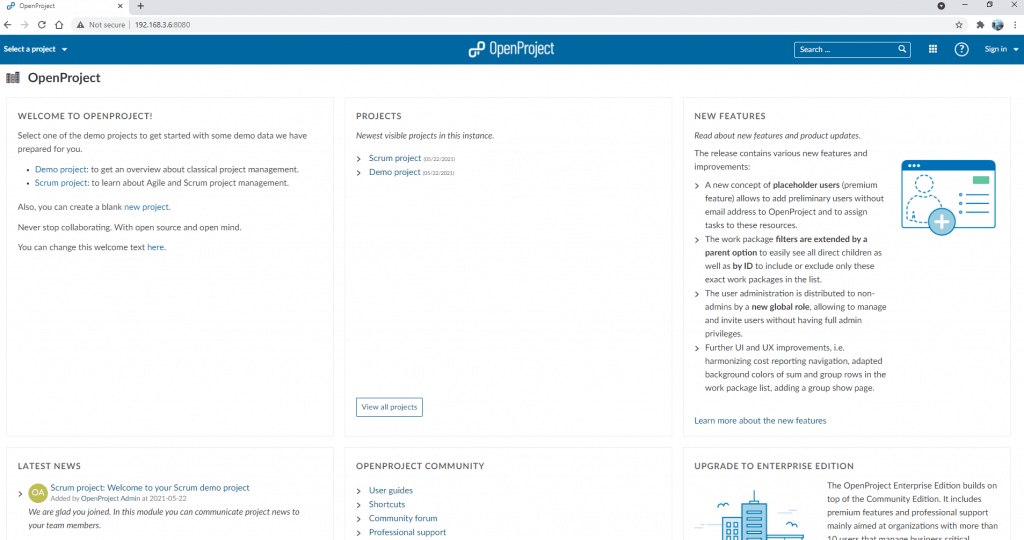
How to deploy with docker
sudo mkdir -p /var/lib/myopenproject/{pgdata,assets}
head /dev/urandom | tr -dc A-Za-z0-9 | head -c 32 ; echo '' # The random key generated for SECRET_KEY_BASE variable.Deploy the OpenProject containers with the command:
docker run -d -p 8080:80 --name myopenproject -e SECRET_KEY_BASE=secret -v /var/lib/myopenproject/pgdata:/var/myopenproject/pgdata -v /var/lib/myopenproject/assets:/var/myopenproject/assets openproject/community:11The output terminal is as below:
root@DevopsRoles:~/myopenproject/compose# head /dev/urandom | tr -dc A-Za-z0-9 | head -c 32 ; echo ''
HgRwijSjJXYBHRl8MSPfm7oiYd0F5hmK
root@DevopsRoles:~/myopenproject/compose# docker run -d -p 8080:80 --name myopenproject -e SECRET_KEY_BASE=HgRwijSjJXYBHRl8MSPfm7oiYd0F5hmK -v /var/lib/myopenproject/pgdata:/var/myopenproject/pgdata -v /var/lib/myopenproject/assets:/var/myopenproject/assets openproject/community:11
24c5f3fb9b560f4eca821555a50d8cab8ef7b3e38616071db9083ed2784219fe
root@DevopsRoles:~/myopenproject/compose# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
24c5f3fb9b56 openproject/community:11 "./docker/prod/entry…" 5 seconds ago Up 4 seconds 5432/tcp, 0.0.0.0:8080->80/tcp myopenproject
root@DevopsRoles:~/myopenproject/compose# netstat -nplt
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 127.0.0.1:38701 0.0.0.0:* LISTEN 15247/containerd
tcp 0 0 0.0.0.0:8080 0.0.0.0:* LISTEN 19208/docker-proxy
tcp 0 0 127.0.0.53:53 0.0.0.0:* LISTEN 599/systemd-resolve
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 1091/sshd: /usr/sbi
tcp6 0 0 :::22 :::* LISTEN 1091/sshd: /usr/sbiConclusion
You have to deploy the OpenProject platform as a Docker Container. I hope will this your helpful. Thank you for reading the DevopsRoles page! deploy OpenProject.