

Introduction: Managing deployments is hard, but mastering promotion across Kubernetes and hybrid environments is a completely different beast.
Most engineers vastly underestimate the complexity involved.
They think a simple Jenkins pipeline will magically sync their on-prem data centers with AWS. *They are wrong.*
I know this because, back in 2018, I completely nuked a production cluster trying to promote a simple microservice.
My traditional CI/CD scripts simply couldn’t handle the network latency and configuration drift.

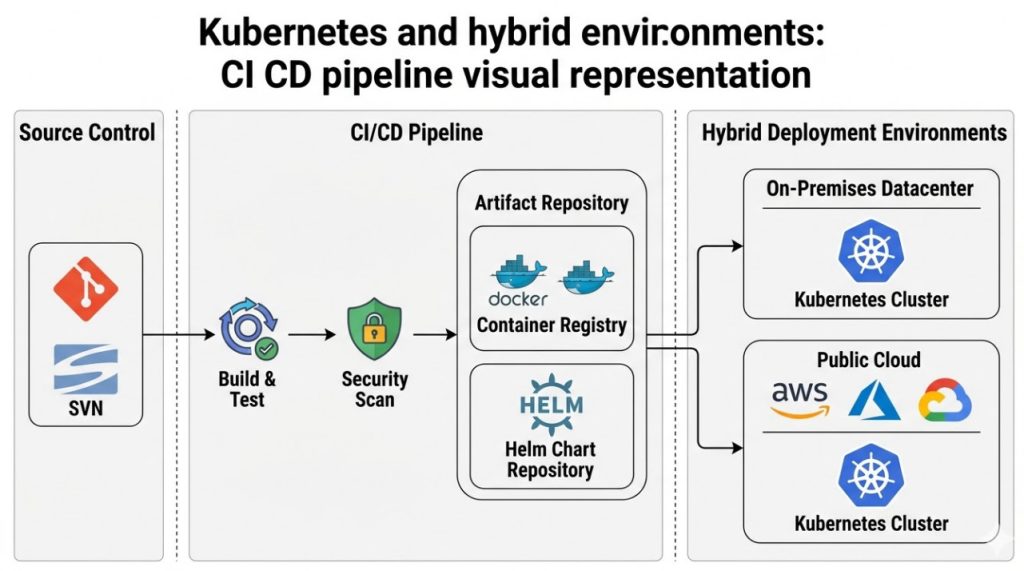
Table of Contents
- 1 The Brutal Reality of Kubernetes and Hybrid Environments
- 2 Strategy 1: Embrace GitOps for Promotion Across Kubernetes and Hybrid Environments
- 3 Strategy 2: Decoupling Configuration in Kubernetes and Hybrid Environments
- 4 Strategy 3: Handling Secrets Securely
- 5 Strategy 4: Advanced Traffic Routing
- 6 Strategy 5: Consistent Observability Across Kubernetes and Hybrid Environments
- 7 Strategy 6: Immutable Artifacts
- 8 Strategy 7: Automated Conformance Testing
The Brutal Reality of Kubernetes and Hybrid Environments
Why is this so difficult? Let’s talk about the elephant in the room.
When you split workloads between bare-metal servers and cloud providers, you lose the comfort of a unified network.
Network policies, ingress controllers, and storage classes suddenly require completely different configurations per environment.
If you don’t build a bulletproof strategy, your team will spend hours debugging parity issues.
So, why does this matter?
Because downtime in Kubernetes and hybrid environments costs thousands of dollars per minute.
Strategy 1: Embrace GitOps for Promotion Across Kubernetes and Hybrid Environments
Forget manual `kubectl apply` commands. That is a recipe for disaster.
If you are operating at scale, your Git repository must be the single source of truth.
Tools like ArgoCD or Flux monitor your Git repos and automatically synchronize your clusters.
When you want to promote an application from staging to production, you simply merge a pull request.
Here is what a basic ArgoCD Application manifest looks like:
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: payment-service-prod
namespace: argocd
spec:
project: default
source:
repoURL: 'https://github.com/myorg/my-k8s-manifests.git'
path: kustomize/overlays/production
targetRevision: HEAD
destination:
server: 'https://kubernetes.default.svc'
namespace: production
syncPolicy:
automated:
prune: true
selfHeal: true
Notice how clean that is?
This approach completely decouples your Continuous Integration (CI) from your Continuous Deployment (CD).
Strategy 2: Decoupling Configuration in Kubernetes and Hybrid Environments
You cannot use the exact same manifests for on-premise and cloud clusters.
AWS might use an Application Load Balancer, while your on-premise cluster relies on MetalLB.
This is where Kustomize becomes your best friend.
Kustomize allows you to define a “base” configuration and apply “overlays” for specific targets.
- Base: Contains your Deployment, Service, and common labels.
- Overlay (AWS): Patches the Service to use an AWS-specific Ingress class.
- Overlay (On-Prem): Adjusts resource limits for older hardware constraints.
This minimizes code duplication and severely reduces human error.
Strategy 3: Handling Secrets Securely
Security is the biggest pain point I see clients face today.
You cannot check passwords into Git. Seriously, don’t do it.
When dealing with Kubernetes and hybrid environments, you need an external secret management system.
I strongly recommend using HashiCorp Vault or the External Secrets Operator.
These tools fetch secrets from your cloud provider (like AWS Secrets Manager) and inject them directly into your pods.
For more details, check the official documentation and recent news updates on promotion strategies.
Strategy 4: Advanced Traffic Routing
A standard deployment strategy replaces old pods with new ones.
In highly sensitive platforms, this is far too risky.
You must implement Canary releases or Blue/Green deployments.
This involves shifting a small percentage of user traffic (e.g., 5%) to the new version.
If errors spike, you instantly roll back.
Service meshes like Istio make this incredibly straightforward.
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: checkout-service
spec:
hosts:
- checkout.mycompany.com
http:
- route:
- destination:
host: checkout-service
subset: v1
weight: 90
- destination:
host: checkout-service
subset: v2
weight: 10
This YAML instantly diverts 10% of traffic to version 2.
If you aren’t doing this, you are flying blind.
Strategy 5: Consistent Observability Across Kubernetes and Hybrid Environments
Logs and metrics are your only lifeline when things break.
But when half your apps are on-prem and half are in GCP, monitoring is a nightmare.
You need a unified observability plane.
Standardize on Prometheus for metrics and Fluentd (or Promtail) for log forwarding.
Ship everything to a centralized Grafana instance or a SaaS provider like Datadog.
Do not rely on local cluster dashboards.
If a cluster goes down, you lose the dashboard too. Think about it.
Strategy 6: Immutable Artifacts
This is a rule I enforce ruthlessly.
Once a Docker image is built, it must never change.
You do not rebuild your image for different environments.
You build it once, tag it with a commit SHA, and promote that exact same image.
This guarantees that the code you tested in staging is the exact code running in production.
If you need environment-specific tweaks, use ConfigMaps and environment variables.
For a deeper dive into pipeline architectures, check out my guide on [Internal Link: Advanced CI/CD Pipeline Architectures].
Strategy 7: Automated Conformance Testing
How do you know the environment is ready for promotion?
You run automated tests directly inside the target cluster.
Tools like Sonobuoy or custom Helm test hooks are invaluable here.
Before ArgoCD considers a deployment “healthy”, it should wait for these tests to pass.
If they fail, the pipeline halts.
It acts as an automated safety net for your Kubernetes and hybrid environments.
Never rely solely on human QA for infrastructure validation.
FAQ Section
- What is the biggest challenge with hybrid Kubernetes? Managing network connectivity and consistent storage classes across disparate infrastructure providers.
- Is Jenkins dead for Kubernetes deployments? Not dead, but it should be restricted to CI (building and testing). Leave CD (deploying) to GitOps tools.
- How do I handle database migrations? Run them as Kubernetes Jobs via Helm pre-upgrade hooks before the main application pods roll out.
- Should I use one large cluster or many small ones? For hybrid, many smaller, purpose-built clusters (multi-cluster architecture) are generally safer and easier to manage.

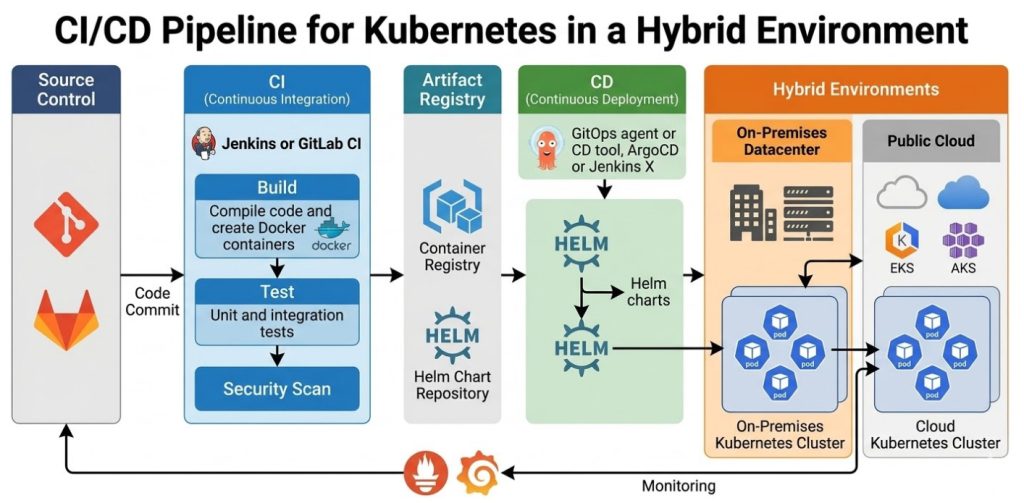
Conclusion: Mastering software promotion across Kubernetes and hybrid environments requires discipline, the right tooling, and an absolute refusal to perform manual updates. Stop treating your infrastructure like pets, adopt GitOps, and watch your deployment anxiety disappear. Thank you for reading the DevopsRoles page!