Introduction: Let me tell you about a 3 AM pager alert that nearly ended my career, and why an Istio service mesh became the only thing standing between my team and total infrastructure collapse.
We had just rolled out a massive cluster of AI microservices. It was supposed to be a glorious, highly-scalable deployment.
Instead, traffic routing failed immediately. Latency spiked to 15 seconds, and our expensive GPU nodes choked on backlogged requests.
Standard Kubernetes networking just couldn’t handle the heavy, persistent connections required by large language models (LLMs).
If you are building AI applications today without a dedicated networking layer, you are sitting on a ticking time bomb.
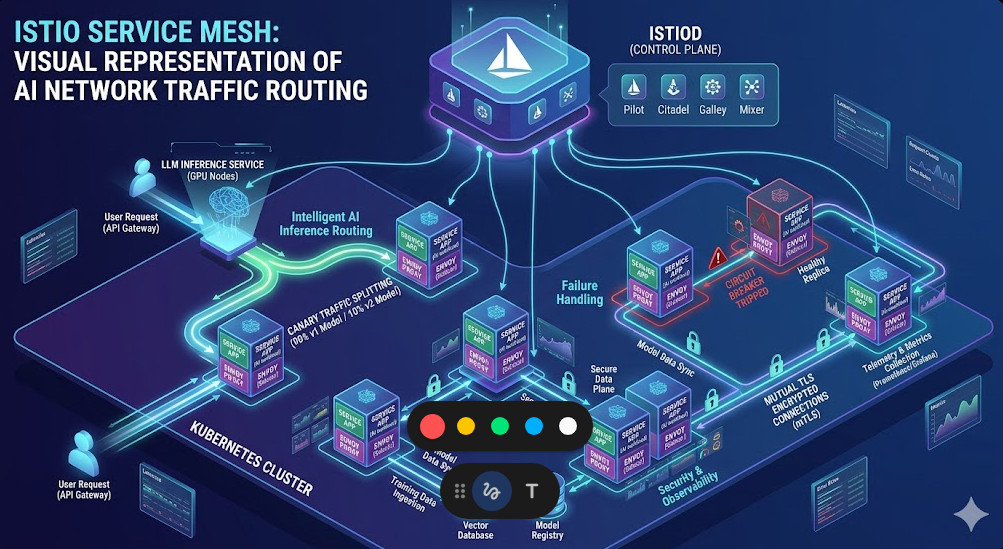
Table of Contents
Why Your AI Strategy Fails Without an Istio Service Mesh
So, why does this matter? AI workloads are fundamentally different from your standard web application traffic.
A typical web request is tiny. It hits a database, grabs some text, and returns in milliseconds. Standard ingress controllers handle this perfectly.
AI inference requests are massive. A single user prompt might contain thousands of tokens, taking seconds to process while holding a connection open.
When you have thousands of these simultaneous connections, dumb round-robin load balancing will destroy your cluster.
It will send heavy requests to a pod that is already maxed out at 100% GPU utilization, causing terrifying timeout cascades.
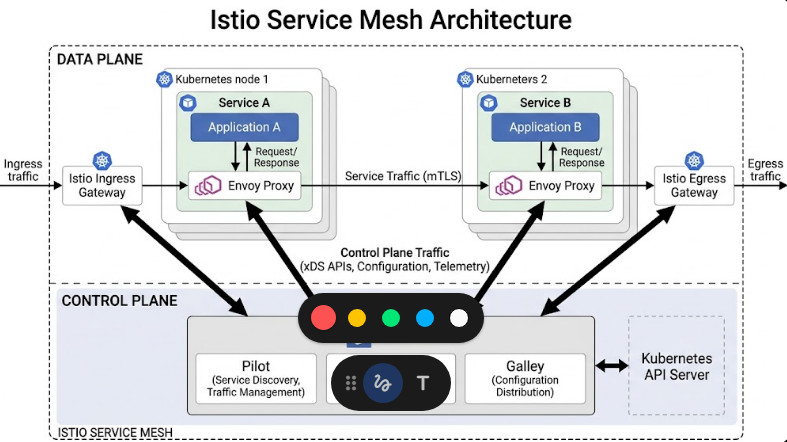
This is where an Istio service mesh steps in. It provides intelligent, Layer 7 (Application Layer) load balancing.
It looks at the actual queue depth of your pods and routes traffic only to the containers that have the capacity to think.
If you want to understand the baseline mechanics of orchestrating these containers, check out this [Internal Link: Kubernetes Networking Best Practices] guide.
The ‘Future-Ready’ Promise of AI Networking
I keep hearing architects talk about building “future-proof” systems. Let’s be honest, in tech, that’s a myth.
But building something “future-ready” is entirely possible, and it requires decoupling your networking logic from your application code.
Recently, the industry has started catching on. For a deeper look at this massive shift, read this recent industry report.
They hit the nail on the head. We have to weave a secure fabric around our models.
You cannot rely on your Python developers to write custom retry logic, circuit breakers, and mutual TLS encryption into every single FastAPI wrapper.
They will get it wrong, and it will slow down your feature velocity to a crawl.
Zero-Trust Security for Models
Consider the data you are feeding into your enterprise LLMs. It’s often proprietary source code, PII, or financial records.
If an attacker compromises a single low-level microservice in your cluster, they can theoretically sniff the unencrypted traffic passing between your pods.
Istio solves this by enforcing mutual TLS (mTLS) by default. Every single byte of data moving between your AI models is encrypted.
The best part? Your application code has no idea. The proxy handles the certificate rotation and encryption entirely transparently.
For more on the underlying proxy technology, you can review the Envoy GitHub repository.
Deploying an Istio Service Mesh for LLMs
Let’s look at a war story from my last gig. We were migrating from a fast, cheap model (let’s call it Model A) to a slower, more accurate model (Model B).
We couldn’t just flip a switch. We needed to test Model B with real production traffic, but only 5% of it.
Without an Istio service mesh, doing this at the network layer is incredibly painful. With it, it’s just a few lines of YAML.
We used a VirtualService to cleanly slice our traffic. Here is exactly how we did it.
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: llm-routing
spec:
hosts:
- ai-inference-service
http:
- route:
- destination:
host: ai-inference-service
subset: v1-fast-model
weight: 95
- destination:
host: ai-inference-service
subset: v2-smart-model
weight: 5
This simple configuration saved us from a disastrous rollout. We monitored the error rates on the 5% split.
Once we confirmed the GPUs weren’t melting, we dialed it up to 20%, then 50%, and finally 100%.
That is the power of decoupled infrastructure.
The Performance Tax: Is an Istio Service Mesh Too Slow?
I know what you’re thinking. “You want me to put a proxy in front of every single AI container? Won’t that kill my latency?”
It’s a valid fear. Historically, the sidecar pattern did introduce a minor latency tax—usually around 2 to 5 milliseconds per hop.
For a basic CRUD app, you wouldn’t notice. For a high-frequency trading bot, it’s a dealbreaker. But for AI?
Your LLM takes 800 milliseconds just to generate the first token. The 3ms proxy overhead is a rounding error.
More importantly, the time you save by preventing retries and connection drops massively outweighs the proxy tax.
However, the Istio service mesh ecosystem isn’t standing still.
Sidecarless Architecture (Ambient Mesh)
The community recently introduced Ambient Mesh, a sidecarless data plane alternative.
Instead of injecting a proxy into every pod, it uses a shared node-level proxy called a ztunnel for secure L4 transport.
If you need L7 routing (like our traffic splitting example above), you deploy a specific Waypoint proxy only where needed.
This drastically reduces CPU and memory overhead across your cluster, freeing up those precious resources for your actual compute workloads.
You can read the technical specifications on the Istio official documentation site.
My 3 Rules for Scaling AI Networks
Over the last decade, I’ve watched countless cloud-native architectures crumble under load.
If you take nothing else away from this article, memorize these three rules for surviving AI scale.
- Rule 1: Never trust default timeouts. Kubernetes assumes requests finish quickly. AI requests don’t. Hardcode aggressive, explicit timeouts for every service call to prevent cascading failures.
- Rule 2: Circuit breakers are mandatory. If an inference node starts failing, cut it off immediately. Do not keep sending it traffic.
- Rule 3: Tracing is not optional. You must know exactly how long a request spent in the queue versus how long it spent computing.
Let’s look at how to enforce Rule 2 using an Istio DestinationRule.
Setting up Circuit Breakers
This configuration will eject a pod from the load balancing pool for 3 minutes if it returns 5 consecutive 5xx server errors.
apiVersion: networking.istio.io/v1alpha3
kind: DestinationRule
metadata:
name: llm-circuit-breaker
spec:
host: ai-inference-service
trafficPolicy:
outlierDetection:
consecutive5xxErrors: 5
interval: 10s
baseEjectionTime: 3m
maxEjectionPercent: 100
I cannot stress enough how many outages this exact snippet of code has prevented for my teams.
It allows the sick pod to reboot and clear its VRAM without dragging the rest of the application down with it.
In the world of modern cloud computing, assuming failure is the only way to ensure uptime.
FAQ Section
- Does an Istio service mesh work with standard managed Kubernetes? Yes, it runs perfectly on EKS, GKE, and AKS. You just install the control plane via Helm.
- Is it incredibly hard to learn? I won’t lie, the learning curve is steep. But the YAML APIs are declarative and logical once you grasp the basics.
- Do I need it if I only have two microservices? Probably not. A mesh pays dividends when you have complex routing, strict security compliance, or 10+ interacting services.
Conclusion: We are entering an era where application logic and network logic must be completely separated.
AI workloads are too brittle, too expensive, and too slow to be managed by basic ingress controllers.
By implementing an Istio service mesh, you aren’t just adding another tool to your stack; you are building an insurance policy.
You are ensuring that when your models inevitably face a massive spike in traffic, your infrastructure will bend, but it won’t break. Thank you for reading the DevopsRoles page!

