Managing and scaling your Amazon OpenSearch Service (OpenSearch) deployments can be a complex undertaking. Ensuring efficient data ingestion is critical for leveraging the power of OpenSearch for analytics and logging. This comprehensive guide delves into how Terraform OpenSearch Ingestion simplifies this process, allowing you to automate the provisioning and management of your OpenSearch ingestion pipelines. We’ll explore various methods, best practices, and troubleshooting techniques to help you confidently manage your OpenSearch data flow using Terraform.
Table of Contents
Understanding the Need for Automated OpenSearch Ingestion
Manually configuring and managing OpenSearch ingestion pipelines is time-consuming and error-prone. As your data volume and complexity grow, managing these pipelines becomes increasingly challenging. This is where Infrastructure as Code (IaC) tools, like Terraform, shine. Terraform OpenSearch Ingestion enables you to define your entire ingestion infrastructure as code, allowing for consistent, repeatable, and auditable deployments.
Benefits of using Terraform for OpenSearch Ingestion include:
- Automation: Automate the creation, modification, and deletion of your ingestion pipelines.
- Reproducibility: Easily recreate your infrastructure in different environments.
- Version Control: Track changes to your infrastructure using Git and other version control systems.
- Collaboration: Work collaboratively on infrastructure definitions.
- Scalability: Easily scale your ingestion pipelines to handle growing data volumes.
Terraform OpenSearch Ingestion: Practical Implementation
This section demonstrates how to leverage Terraform to manage OpenSearch ingestion. We will focus on a common scenario: creating an OpenSearch domain and configuring an ingestion pipeline using the AWS SDK for Java. While this example uses Java, the principles apply to other languages as well. Remember to replace placeholders like `your-domain-name`, `your-key`, etc. with your actual values.
Setting up the Terraform Environment
First, ensure you have Terraform installed and configured. You’ll also need AWS credentials properly configured for your Terraform provider to access AWS resources. Consider using an IAM role for enhanced security.
Creating the OpenSearch Domain
resource "aws_opensearch_domain" "default" {
domain_name = "your-domain-name"
engine_version = "2.6" # or latest supported version
cluster_config {
instance_type = "t3.medium.elasticsearch"
instance_count = 3
}
ebs_options {
ebs_enabled = true
volume_size = 10
volume_type = "gp2"
}
}
Configuring the Ingestion Pipeline (Example using Java)
This example outlines the basic structure. A complete implementation would involve details specific to your data source and schema. You would typically use a library like the AWS SDK for Java to interact with OpenSearch.
// Java code to ingest data into OpenSearch (simplified example)
// ... (Import necessary AWS SDK libraries) ...
AmazonOpenSearchClient client = AmazonOpenSearchClientBuilder.standard()
.withCredentials(DefaultAWSCredentialsProviderChain.getInstance())
.withRegion(Regions.US_EAST_1) // Replace with your region
.build();
// ... (Data preparation and transformation logic) ...
BulkRequest bulkRequest = new BulkRequest();
// ... (Add documents to the bulk request) ...
BulkResponse bulkResponse = client.bulk(bulkRequest);
if (bulkResponse.hasFailures()) {
// Handle failures
}
// ... (Close the client) ...
This Java code would then be packaged and deployed as a part of your infrastructure, likely using a separate service like AWS Lambda or an EC2 instance managed by Terraform.
Connecting the Pipeline to Terraform
Within your Terraform configuration, you would manage the deployment of the application (Lambda function, EC2 instance, etc.) responsible for data ingestion. This could involve using resources like aws_lambda_function or aws_instance, depending on your chosen method. The crucial point is that Terraform manages the entire infrastructure, ensuring its consistent and reliable deployment.
Advanced Terraform OpenSearch Ingestion Techniques
This section explores more advanced techniques to refine your Terraform OpenSearch Ingestion strategy.
Using Data Sources
Terraform data sources allow you to retrieve information about existing AWS resources. This is useful when integrating with pre-existing components or managing dependencies.
data "aws_opensearch_domain" "existing" {
domain_name = "your-existing-domain"
}
output "endpoint" {
value = data.aws_opensearch_domain.existing.endpoint
}
Implementing Security Best Practices
Prioritize security when designing your ingestion pipelines. Use IAM roles to restrict access to OpenSearch and other AWS services. Avoid hardcoding credentials directly in your Terraform configuration.
- Use IAM roles for access control.
- Encrypt data both in transit and at rest.
- Regularly review and update security configurations.
Monitoring and Logging
Implement robust monitoring and logging to track the health and performance of your ingestion pipelines. Integrate with services like CloudWatch to gain insights into data flow and identify potential issues.
Terraform OpenSearch Ingestion: Best Practices
- Modularization: Break down your Terraform code into reusable modules for better organization and maintainability.
- Version Control: Use Git or a similar version control system to track changes and collaborate effectively.
- Testing: Implement thorough testing to catch errors early in the development cycle. Consider using Terraform’s testing features.
- State Management: Properly manage your Terraform state to prevent accidental infrastructure modifications.
Frequently Asked Questions
Q1: What are the different ways to ingest data into OpenSearch using Terraform?
Several approaches exist for Terraform OpenSearch Ingestion. You can use AWS services like Lambda functions, EC2 instances, or managed services like Kinesis to process and ingest data into OpenSearch. The choice depends on your specific requirements and data volume.
Q2: How can I handle errors during ingestion using Terraform?
Implement error handling within your ingestion pipeline (e.g., using try-catch blocks in your code). Configure logging and monitoring to track and analyze errors. Terraform itself doesn’t directly manage runtime errors within your ingestion code; it focuses on the infrastructure.
Q3: Can I use Terraform to manage OpenSearch dashboards and visualizations?
While Terraform primarily manages infrastructure, you can indirectly manage aspects of OpenSearch dashboards. This often involves using custom scripts or applications deployed through Terraform to create and update dashboards programmatically. Direct management of dashboard definitions within Terraform is not natively supported.
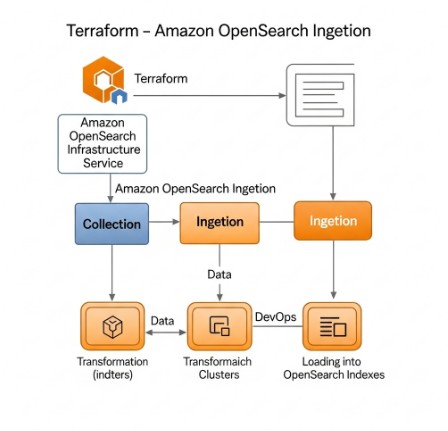
Conclusion
Effectively managing Terraform OpenSearch Ingestion is crucial for leveraging the full potential of OpenSearch. By embracing IaC principles and using Terraform, you gain automation, reproducibility, and scalability for your data ingestion pipelines. Remember to prioritize security and implement robust monitoring and logging to ensure a reliable and efficient data flow. Mastering Terraform OpenSearch Ingestion empowers you to build and maintain a robust and scalable data analytics platform.
For further information, refer to the official Terraform documentation and the AWS OpenSearch Service documentation. Thank you for reading the DevopsRoles page!

