For the modern enterprise, the question is no longer if you will adopt cloud-native orchestration, but how you will manage the transition. Kubernetes migration is rarely a linear process; it is a complex architectural shift that demands a rigorous understanding of distributed systems, state persistence, and networking primitives. Whether you are moving legacy monoliths from bare metal to K8s, or orchestrating a multi-cloud cluster-to-cluster shift, the margin for error is nonexistent.
This guide is designed for Senior DevOps Engineers and SREs. We will bypass the introductory concepts and dive straight into the strategic patterns, technical hurdles of stateful workloads, and zero-downtime cutover techniques required for a successful production migration.
Table of Contents
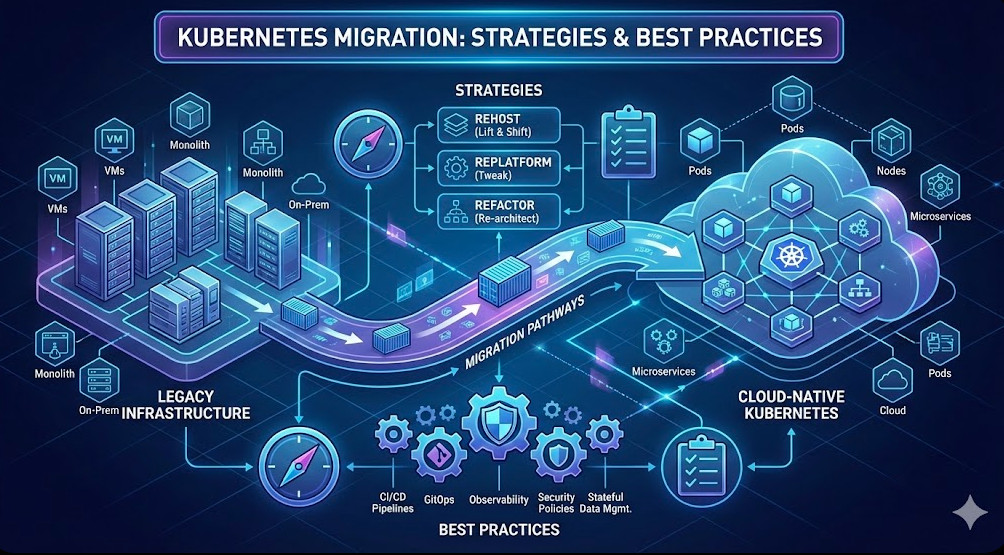
The Architectural Landscape of Migration
A successful Kubernetes migration is 20% infrastructure provisioning and 80% application refactoring and data gravity management. Before a single YAML manifest is applied, the migration path must be categorized based on the source and destination architectures.
Types of Migration Contexts
- V2C (VM to Container): The classic modernization path. Requires containerization (Dockerfiles), defining resource limits, and decoupling configuration from code (12-Factor App adherence).
- C2C (Cluster to Cluster): Moving from on-prem OpenShift to EKS, or GKE to EKS. This involves handling API version discrepancies, CNI (Container Network Interface) translation, and Ingress controller mapping.
- Hybrid/Multi-Cloud: Spanning workloads across clusters. Complexity lies in service mesh implementation (Istio/Linkerd) and consistent security policies.
GigaCode Pro-Tip: In C2C migrations, strictly audit your API versions using tools like
kubent(Kube No Trouble) before migration. Deprecated APIs in the source cluster (e.g.,v1beta1Ingress) will cause immediate deployment failures in a newer destination cluster version.
Strategic Patterns: The 6 Rs in a K8s Context
While the “6 Rs” of cloud migration are standard, their application in a Kubernetes migration is distinct.
1. Rehost (Lift and Shift)
Wrapping a legacy binary in a container without code changes. While fast, this often results in “fat containers” that behave like VMs (using SupervisorD, lacking liveness probes, local logging).
Best for: Low-criticality internal apps or immediate datacenter exits.
2. Replatform (Tweak and Shift)
Moving to containers while replacing backend services with cloud-native equivalents. For example, migrating a local MySQL instance inside a VM to Amazon RDS or Google Cloud SQL, while the application moves to Kubernetes.
3. Refactor (Re-architect)
Breaking a monolith into microservices to fully leverage Kubernetes primitives like scaling, self-healing, and distinct release cycles.
Technical Deep Dive: Migrating Stateful Workloads
Stateless apps are trivial to migrate. The true challenge in any Kubernetes migration is Data Gravity. Handling StatefulSets and PersistentVolumeClaims (PVCs) requires ensuring data integrity and minimizing Return to Operation (RTO) time.
CSI and Volume Snapshots
Modern migrations rely heavily on the Container Storage Interface (CSI). If you are migrating between clusters (C2C), you cannot simply “move” a PV. You must replicate the data.
Migration Strategy: Velero with Restic/Kopia
Velero is the industry standard for backing up and restoring Kubernetes cluster resources and persistent volumes. For storage backends that do not support native snapshots across different providers, Velero integrates with Restic (or Kopia in newer versions) to perform file-level backups of PVC data.
# Example: Creating a backup including PVCs using Velero
velero backup create migration-backup \
--include-namespaces production-app \
--default-volumes-to-fs-backup \
--wait
Upon restoration in the target cluster, Velero reconstructs the Kubernetes objects (Deployments, Services, PVCs) and hydrates the data into the new StorageClass defined in the destination.
Database Migration Patterns
For high-throughput databases, file-level backup/restore is often too slow (high downtime). Instead, utilize replication:
- Setup a Replica: Configure a read-replica in the destination Kubernetes cluster (or managed DB service) pointing to the source master.
- Sync: Allow replication lag to drop to near zero.
- Promote: During the maintenance window, stop writes to the source, wait for the final sync, and promote the destination replica to master.
Zero-Downtime Cutover Strategies
Once the workload is running in the destination environment, switching traffic is the highest-risk phase. A “Big Bang” DNS switch is rarely advisable for high-traffic systems.
1. DNS Weighted Routing (Canary Cutover)
Utilize DNS providers (like AWS Route53 or Cloudflare) to shift traffic gradually. Start with a 5% weight to the new cluster’s Ingress IP.
2. Ingress Shadowing (Dark Traffic)
Before the actual cutover, mirror production traffic to the new cluster to validate performance without affecting real users. This can be achieved using Service Mesh capabilities (like Istio) or Nginx ingress annotations.
# Example: Nginx Ingress Mirroring Annotation
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: production-ingress
annotations:
nginx.ingress.kubernetes.io/mirror-target-service: "new-cluster-endpoint"
spec:
rules:
- host: api.example.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: legacy-service
port:
number: 80
CI/CD and GitOps Adaptation
A Kubernetes migration is the perfect opportunity to enforce GitOps. Migrating pipeline logic (Jenkins, GitLab CI) directly to Kubernetes manifests managed by ArgoCD or Flux ensures that the “source of truth” for your infrastructure is version controlled.
When migrating pipelines:
- Abstraction: Replace complex imperative deployment scripts (
kubectl apply -f ...) with Helm Charts or Kustomize overlays. - Secret Management: Move away from environment variables stored in CI tools. Adopt Secrets Store CSI Driver (Vault/AWS Secrets Manager) or Sealed Secrets.
Frequently Asked Questions (FAQ)
How do I handle disparate Ingress Controllers during migration?
If moving from AWS ALB Ingress to Nginx Ingress, the annotations will differ significantly. Use a “Translation Layer” approach: Use Helm to template your Ingress resources. Define values files for the source (ALB) and destination (Nginx) that render the correct annotations dynamically, allowing you to deploy to both environments from the same codebase during the transition.
What is the biggest risk in Kubernetes migration?
Network connectivity and latency. Often, migrated services in the new cluster need to communicate with legacy services left behind on-prem or in a different VPC. Ensure you have established robust peering, VPNs, or Transit Gateways before moving applications to prevent timeouts.
Should I migrate stateful workloads to Kubernetes at all?
This is a contentious topic. For experts, the answer is: “Yes, if you have the operational maturity.” Operators (like the Prometheus Operator or Postgres Operator) make managing stateful apps easier, but if your team lacks deep K8s storage knowledge, offloading state to managed services (RDS, Cloud SQL) lowers the migration risk profile significantly.
Conclusion
Kubernetes migration is a multifaceted engineering challenge that extends far beyond simple containerization. It requires a holistic strategy encompassing data persistence, traffic shaping, and observability.
By leveraging tools like Velero for state transfer, adopting GitOps for configuration consistency, and utilizing weighted DNS for traffic cutovers, you can execute a migration that not only modernizes your stack but does so with minimal risk to the business. The goal is not just to be on Kubernetes, but to operate a platform that is resilient, scalable, and easier to manage than the legacy system it replaces. Thank you for reading the DevopsRoles page!
