In the world of Machine Learning Operations (MLOps), achieving consistency, reproducibility, and scalability is the ultimate goal. Manually deploying and managing the complex infrastructure required for ML workflows is fraught with challenges, including configuration drift, human error, and a lack of version control. This is where Infrastructure as Code (IaC) becomes a game-changer. This article provides an in-depth, practical guide on how to leverage Terraform, a leading IaC tool, to define, deploy, and manage robust ML Pipelines with Terraform on Amazon SageMaker, transforming your MLOps workflow from a manual chore into an automated, reliable process.
By the end of this guide, you will understand the core principles of using Terraform for MLOps, learn how to structure a production-ready project, and be equipped with the code and knowledge to deploy your own SageMaker pipelines with confidence.
Table of Contents
- 1 Why Use Terraform for SageMaker ML Pipelines?
- 2 Core AWS and Terraform Components for a SageMaker Pipeline
- 3 A Step-by-Step Guide to Deploying ML Pipelines with Terraform
- 4 Advanced Concepts and Best Practices
- 5 Frequently Asked Questions
- 6 Conclusion
Why Use Terraform for SageMaker ML Pipelines?
While you can create SageMaker pipelines through the AWS Management Console or using the AWS SDKs, adopting an IaC approach with Terraform offers significant advantages that are crucial for mature MLOps practices.
- Reproducibility: Terraform’s declarative syntax allows you to define your entire ML infrastructure—from S3 buckets and IAM roles to the SageMaker Pipeline itself—in version-controlled configuration files. This ensures you can recreate the exact same environment anytime, anywhere, eliminating the “it works on my machine” problem.
- Version Control and Collaboration: Storing your infrastructure definition in a Git repository enables powerful collaboration workflows. Teams can review changes through pull requests, track the history of every infrastructure modification, and easily roll back to a previous state if something goes wrong.
- Automation and CI/CD: Terraform integrates seamlessly into CI/CD pipelines (like GitHub Actions, GitLab CI, or Jenkins). This allows you to automate the provisioning and updating of your SageMaker pipelines, triggered by code commits, which dramatically accelerates the development lifecycle.
- Reduced Manual Error: Automating infrastructure deployment through code minimizes the risk of human error that often occurs during manual “click-ops” configurations in the AWS console. This leads to more stable and reliable ML systems.
- State Management: Terraform creates a state file that maps your resources to your configuration. This powerful feature allows Terraform to track your infrastructure, plan changes, and manage dependencies effectively, providing a clear view of your deployed resources.
- Multi-Cloud and Multi-Account Capabilities: While this guide focuses on AWS, Terraform’s provider model allows you to manage resources across multiple cloud providers and different AWS accounts using a single, consistent workflow, which is a significant benefit for large organizations.
Core AWS and Terraform Components for a SageMaker Pipeline
Before diving into the code, it’s essential to understand the key resources you’ll be defining. A typical SageMaker pipeline deployment involves more than just the pipeline itself; it requires a set of supporting AWS resources.
Key AWS Resources
- SageMaker Pipeline: The central workflow orchestrator. It’s defined by a series of steps (e.g., processing, training, evaluation, registration) connected by their inputs and outputs.
- IAM Role and Policies: SageMaker needs explicit permissions to access other AWS services like S3 for data, ECR for Docker images, and CloudWatch for logging. You’ll create a dedicated IAM Role that the SageMaker Pipeline execution assumes.
- S3 Bucket: This serves as the data lake and artifact store for your pipeline. All intermediary data, trained model artifacts, and evaluation reports are typically stored here.
- Source Code Repository (Optional but Recommended): Your pipeline definition (often a Python script using the SageMaker SDK) and any custom algorithm code should be stored in a version control system like AWS CodeCommit or GitHub.
- –
- ECR Repository (Optional): If you are using custom algorithms or processing scripts that require specific libraries, you will need an Amazon Elastic Container Registry (ECR) to store your custom Docker images.
Key Terraform Resources
aws_iam_role: Defines the IAM role for SageMaker.aws_iam_role_policy_attachment: Attaches AWS-managed or custom policies to the IAM role.aws_s3_bucket: Creates and configures the S3 bucket for pipeline artifacts.aws_sagemaker_pipeline: The primary Terraform resource used to create and manage the SageMaker Pipeline itself. It takes a pipeline definition (in JSON format) and the IAM role ARN as its main arguments.
A Step-by-Step Guide to Deploying ML Pipelines with Terraform
Now, let’s walk through the practical steps of building and deploying a SageMaker pipeline using Terraform. This example will cover setting up the project, defining the necessary infrastructure, and creating the pipeline resource.
Step 1: Prerequisites
Ensure you have the following tools installed and configured:
- Terraform CLI: Download and install the Terraform CLI from the official HashiCorp website.
- AWS CLI: Install and configure the AWS CLI with your credentials. Terraform will use these credentials to provision resources in your AWS account.
- An AWS Account: Access to an AWS account with permissions to create IAM, S3, and SageMaker resources.
Step 2: Project Structure and Provider Configuration
A well-organized project structure is key to maintainability. Create a new directory for your project and set up the following files:
sagemaker-terraform/
├── main.tf # Main configuration file
├── variables.tf # Input variables
├── outputs.tf # Output values
└── pipeline_definition.json # The SageMaker pipeline definition
In your main.tf, start by configuring the AWS provider:
terraform {
required_providers {
aws = {
source = "hashicorp/aws"
version = "~> 5.0"
}
}
}
provider "aws" {
region = var.aws_region
}In variables.tf, define the variables you’ll use:
variable "aws_region" {
description = "The AWS region to deploy resources in."
type = string
default = "us-east-1"
}
variable "project_name" {
description = "A unique name for the project to prefix resources."
type = string
default = "ml-pipeline-demo"
}Step 3: Defining Foundational Infrastructure (IAM Role and S3)
Your SageMaker pipeline needs an IAM role to execute and an S3 bucket to store artifacts. Add the following resource definitions to your main.tf.
IAM Role for SageMaker
This role allows SageMaker to assume it and perform actions on your behalf.
resource "aws_iam_role" "sagemaker_execution_role" {
name = "${var.project_name}-sagemaker-execution-role"
assume_role_policy = jsonencode({
Version = "2012-10-17",
Statement = [
{
Action = "sts:AssumeRole",
Effect = "Allow",
Principal = {
Service = "sagemaker.amazonaws.com"
}
}
]
})
}
# Attach the AWS-managed policy for full SageMaker access
resource "aws_iam_role_policy_attachment" "sagemaker_full_access" {
role = aws_iam_role.sagemaker_execution_role.name
policy_arn = "arn:aws:iam::aws:policy/AmazonSageMakerFullAccess"
}
# You should ideally create a more fine-grained policy for S3 access
# For simplicity, we attach the S3 full access policy here.
# In production, restrict this to the specific bucket.
resource "aws_iam_role_policy_attachment" "s3_full_access" {
role = aws_iam_role.sagemaker_execution_role.name
policy_arn = "arn:aws:iam::aws:policy/AmazonS3FullAccess"
}S3 Bucket for Artifacts
This bucket will store all data and model artifacts generated by the pipeline.
resource "aws_s3_bucket" "pipeline_artifacts" {
bucket = "${var.project_name}-artifacts-${random_id.bucket_suffix.hex}"
# In a production environment, you should enable versioning, logging, and encryption.
}
# Used to ensure the S3 bucket name is unique
resource "random_id" "bucket_suffix" {
byte_length = 8
}Step 4: Creating the Pipeline Definition
The core logic of your SageMaker pipeline is contained in a JSON definition. This definition outlines the steps, their parameters, and how they connect. While you can write this JSON by hand, it’s most commonly generated using the SageMaker Python SDK. For this example, we will use a simplified, static JSON file named pipeline_definition.json.
Here is a simple example of a pipeline with one processing step:
{
"Version": "2020-12-01",
"Parameters": [
{
"Name": "ProcessingInstanceType",
"Type": "String",
"DefaultValue": "ml.t3.medium"
}
],
"Steps": [
{
"Name": "MyDataProcessingStep",
"Type": "Processing",
"Arguments": {
"AppSpecification": {
"ImageUri": "${processing_image_uri}"
},
"ProcessingInputs": [
{
"InputName": "input-1",
"S3Input": {
"S3Uri": "s3://${s3_bucket_name}/input/raw_data.csv",
"LocalPath": "/opt/ml/processing/input",
"S3DataType": "S3Prefix",
"S3InputMode": "File"
}
}
],
"ProcessingOutputConfig": {
"Outputs": [
{
"OutputName": "train_data",
"S3Output": {
"S3Uri": "s3://${s3_bucket_name}/output/train",
"LocalPath": "/opt/ml/processing/train",
"S3UploadMode": "EndOfJob"
}
}
]
},
"ProcessingResources": {
"ClusterConfig": {
"InstanceCount": 1,
"InstanceType": {
"Get": "Parameters.ProcessingInstanceType"
},
"VolumeSizeInGB": 30
}
}
}
}
]
}Note: This JSON contains placeholders like ${s3_bucket_name} and ${processing_image_uri}. We will replace these dynamically using Terraform.
Step 5: Defining the `aws_sagemaker_pipeline` Resource
This is where everything comes together. We will use Terraform’s templatefile function to read our JSON file and substitute the placeholder values with outputs from our other Terraform resources.
Add this to your main.tf:
resource "aws_sagemaker_pipeline" "main_pipeline" {
pipeline_name = "${var.project_name}-main-pipeline"
role_arn = aws_iam_role.sagemaker_execution_role.arn
# Use the templatefile function to inject dynamic values into our JSON
pipeline_definition = templatefile("${path.module}/pipeline_definition.json", {
s3_bucket_name = aws_s3_bucket.pipeline_artifacts.id
processing_image_uri = "123456789012.dkr.ecr.us-east-1.amazonaws.com/my-processing-image:latest" # Replace with your ECR image URI
})
pipeline_display_name = "My Main ML Pipeline"
pipeline_description = "A demonstration pipeline deployed with Terraform."
tags = {
Project = var.project_name
ManagedBy = "Terraform"
}
}Finally, define an output in outputs.tf to easily retrieve the pipeline’s name after deployment:
output "sagemaker_pipeline_name" {
description = "The name of the deployed SageMaker pipeline."
value = aws_sagemaker_pipeline.main_pipeline.pipeline_name
}
Step 6: Deploy and Execute
You are now ready to deploy your infrastructure.
- Initialize Terraform:
terraform init - Review the plan:
terraform plan - Apply the changes:
terraform apply
After Terraform successfully creates the resources, your SageMaker pipeline will be visible in the AWS Console. You can start a new execution using the AWS CLI:
aws sagemaker start-pipeline-execution --pipeline-name my-ml-pipeline-demo-main-pipelineAdvanced Concepts and Best Practices
Once you have mastered the basics, consider these advanced practices to create more robust and scalable MLOps workflows.
- Use Terraform Modules: Encapsulate your SageMaker pipeline and all its dependencies (IAM role, S3 bucket) into a reusable Terraform module. This allows you to easily stamp out new ML pipelines for different projects with consistent configuration.
- Manage Pipeline Definitions Separately: For complex pipelines, the JSON definition can become large. Consider generating it in a separate CI/CD step using the SageMaker Python SDK and passing the resulting file to your Terraform workflow. This separates ML logic from infrastructure logic.
- CI/CD Automation: Integrate your Terraform repository with a CI/CD system like GitHub Actions. Create a workflow that runs
terraform planon pull requests for review andterraform applyautomatically upon merging to the main branch. - Remote State Management: By default, Terraform stores its state file locally. For team collaboration, use a remote backend like an S3 bucket with DynamoDB for locking. This prevents conflicts and ensures everyone is working with the latest infrastructure state.
Frequently Asked Questions
- Can I use the SageMaker Python SDK directly with Terraform?
Yes, and it’s a common pattern. You use the SageMaker Python SDK in a script to define your pipeline and call the .get_definition() method to export the pipeline’s structure to a JSON file. Your Terraform configuration then reads this JSON file (using file() or templatefile()) and passes it to the aws_sagemaker_pipeline resource. This decouples the Python-based pipeline logic from the HCL-based infrastructure code. - How do I update an existing SageMaker pipeline managed by Terraform?
To update the pipeline, you modify either the pipeline definition JSON file or the variables within your Terraform configuration (e.g., changing an instance type). After making the changes, run terraform plan to see the proposed modifications and then terraform apply to deploy the new version of the pipeline. Terraform will handle the update seamlessly. - Which is better for SageMaker: Terraform or AWS CloudFormation?
Both are excellent IaC tools. CloudFormation is the native AWS solution, offering deep integration and immediate support for new services. Terraform is cloud-agnostic, has a more widely adopted and arguably more readable language (HCL vs. JSON/YAML), and manages state differently, which many users prefer. For teams already using Terraform or those with a multi-cloud strategy, Terraform is often the better choice. For teams exclusively on AWS, the choice often comes down to team preference and existing skills. - How can I pass parameters to my pipeline executions when using Terraform?
Terraform is responsible for defining and deploying the pipeline structure, including defining which parameters are available (the Parameters block in the JSON). The actual values for these parameters are provided when you start an execution, typically via the AWS CLI or SDKs (e.g., using the –pipeline-parameters flag with the start-pipeline-execution command). Your CI/CD script that triggers the pipeline would be responsible for passing these runtime values.
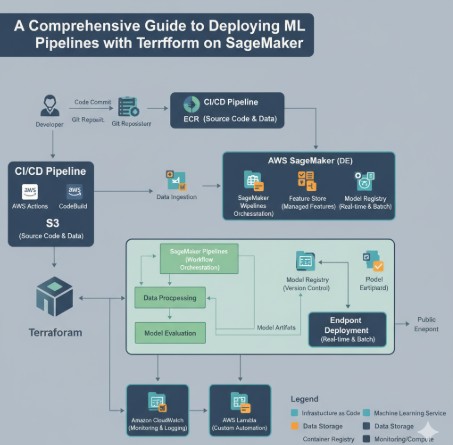
Conclusion
Integrating Infrastructure as Code into your MLOps workflow is no longer a luxury but a necessity for building scalable and reliable machine learning systems. By combining the powerful orchestration capabilities of Amazon SageMaker with the robust declarative framework of Terraform, you can achieve a new level of automation and consistency. Adopting the practice of managing ML Pipelines with Terraform allows your team to version control infrastructure, collaborate effectively through Git-based workflows, and automate deployments in a CI/CD context. This foundational approach not only reduces operational overhead and minimizes errors but also empowers your data science and engineering teams to iterate faster and deliver value more predictably. Thank you for reading the DevopsRoles page!

